论文成果 / Publications
2023
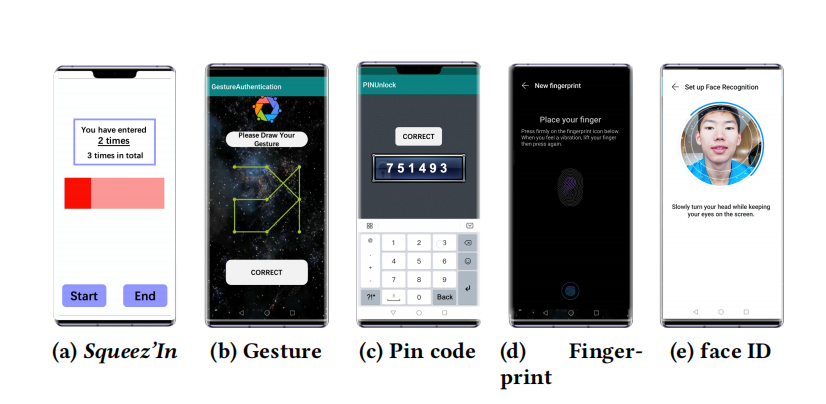
Squeez’In: Private Authentication on Smartphones based on Squeezing Gestures
Abstract
In this paper, we proposed Squeez’In, a technique on smartphonesthat enabled private authentication by holding and squeezing thephone with a unique pattern. We first explored the design space of practical squeezing gestures for authentication by analyzing the participants’ self-designed gestures and squeezing behavior. Results showed that varying-length gestures with two levels of touch pressure and duration were the most natural and unambiguous. We then implemented Squeez’In on an off-the-shelf capacitive sensing smartphone, and employed an SVM-GBDT model for recognizing gestures and user-specific behavioral patterns, achieving 99.3% accuracy and 0.93 F1-score when tested on 21 users. A following 14-day study validated the memorability and long-term stability of Squeez’In. During usability evaluation, compared with gesture and pin code, Squeez’In achieved significantly faster authentication speed and higher user preference in terms of privacy and security.
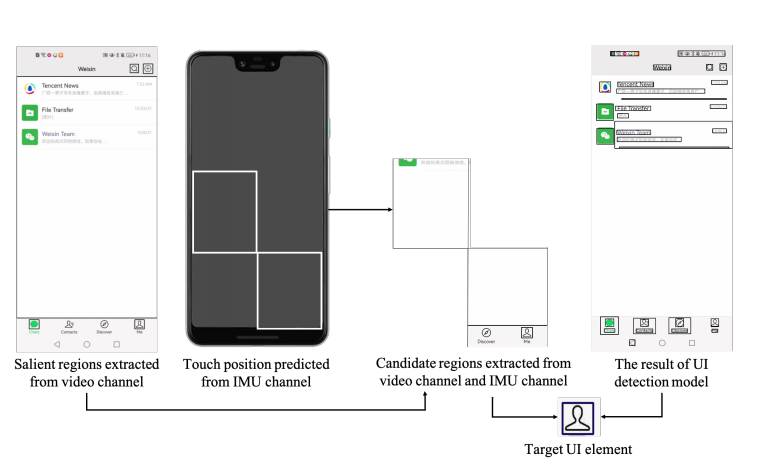
SmartRecorder: An IMU-based Video Tutorial Creation by Demonstration System for Smartphone Interaction Tasks
Abstract
This work focuses on an active topic in the HCI community, namely tutorial creation by demonstration. We present a novel tool named SmartRecorder that facilitates people, without video editing skills, creating video tutorials for smartphone interaction tasks. As automatic interaction trace extraction is a key component to tutorial generation, we seek to tackle the challenges of automatically extracting user interaction traces on smartphones from screencasts. Uniquely, with respect to prior research in this field, we combine computer vision techniques with IMU-based sensing algorithms, and the technical evaluation results show the importance of smartphone IMU data in improving system performance. With the extracted key information of each step, SmartRecorder generates instructional content initially and provides tutorial creators with a tutorial refinement editor designed based on a high recall (99.38%) of key steps to revise the initial instructional content. Finally, SmartRecorder generates video tutorials based on refined instructional content. The
results of the user study demonstrate that SmartRecorder allows non-experts to create smartphone usage video tutorials with less time and higher satisfaction from recipients.
A Human-Computer Collaborative Editing Tool for Conceptual Diagrams
Abstract
Editing (e.g., editing conceptual diagrams) is a typical ofce task that requires numerous tedious GUI operations, resulting in poor interaction efciency and user experience, especially on mobile devices. In this paper, we present a new type of human-computer collaborative editing tool (CET) that enables accurate and efcient editing with little interaction efort. CET divides the task into two parts, and the human and the computer focus on their respective specialties: the human describes high-level editing goals with multimodal commands, while the computer calculates, recommends, and performs detailed operations. We conducted a formative study(N = 16) to determine the concrete task division and implemented the tool on Android devices for the specifc tasks of editing concept diagrams. The user study (N = 24 + 20) showed that it increased
diagram editing speed by 32.75% compared with existing state-of the-art commercial tools and led to better editing results and user experience.

ResType: Invisible and Adaptive Tablet Keyboard Leveraging Resting Fingers
Abstract
Text entry on tablet touchscreens is a basic need nowadays. Tabletkeyboards require visual attention for users to locate keys, thus not supporting efcient touch typing. They also take up a large proportion of screen space, which afects the access to information. To solve these problems, we propose ResType, an adaptive and invisible keyboard on three-state touch surfaces (e.g. tablets with unintentional touch prevention). ResType allows users to rest their hands on it and automatically adapts the keyboard to the resting fngers. Thus, users do not need visual attention to locate keys, which supports touch typing. We quantitatively explored users’ resting fnger patterns on ResType, based on which we proposed an augmented Bayesian decoding algorithm for ResType, with 96.3% top-1 and 99.0% top-3 accuracies. After a 5-day evaluation, ResType achieved 41.26 WPM, outperforming normal tablet keyboards by 13.5% and reaching 86.7% of physical keyboards. It solves the occlusion problem while maintaining comparable typing speed with
current methods on visible tablet keyboards.
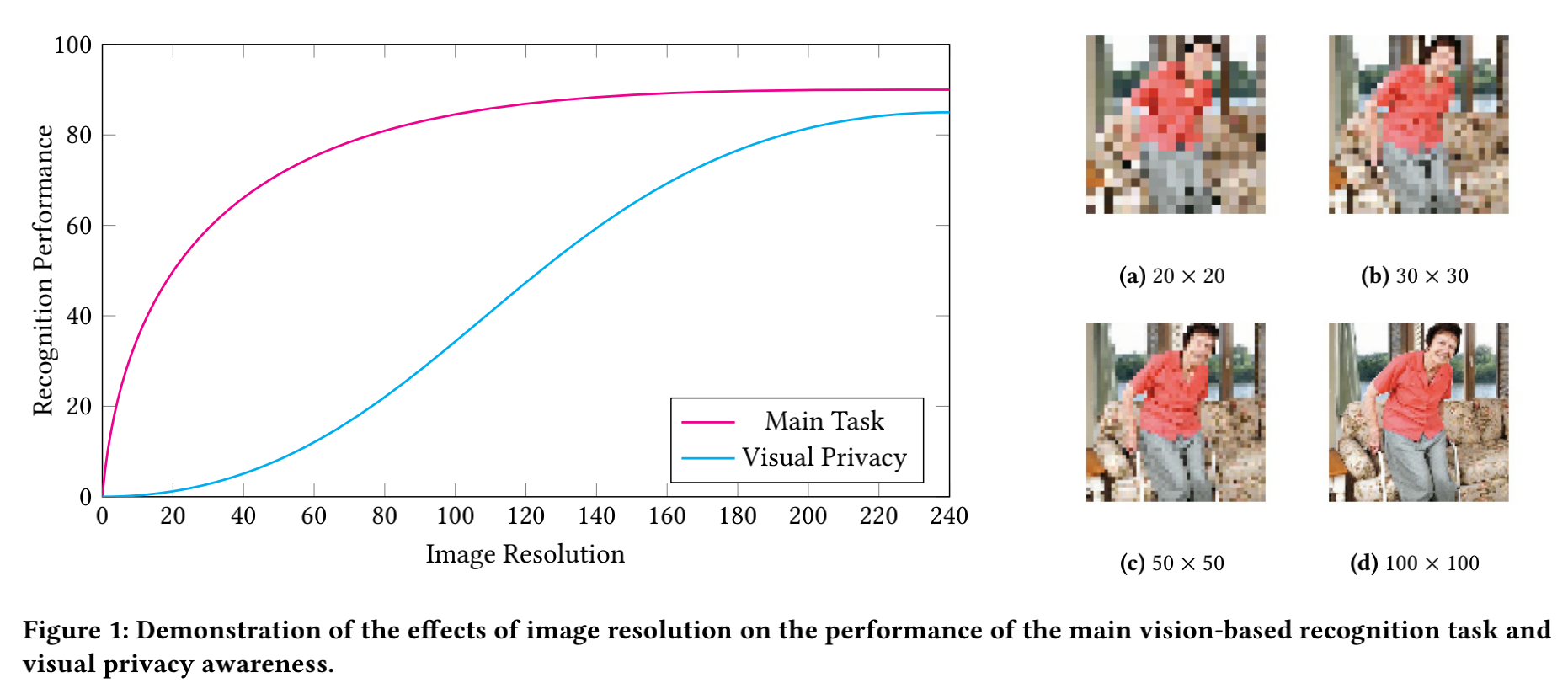
Modeling the Trade-off of Privacy Preservation and Activity Recognition on Low-Resolution Images
Abstract
A computer vision system using low-resolution image sensors can provide intelligent services (e.g., activity recognition) but preserve unnecessary visual privacy information from the hardware level. However, preserving visual privacy and enabling accurate machine recognition have adversarial needs on image resolution.Model-ing the trade-off of privacy preservation and machine recognition performance can guide future privacy-preserving computer vision systems using low-resolution image sensors. In this paper, using the at-home activity of daily livings (ADLs) as the scenario, we first obtained the most important visual privacy features through a user survey. Then we quantified and analyzed the effects of image resolution on human and machine recognition performance in activ-ity recognition and privacy awareness tasks. We also investigated how modern image super-resolution techniques influence these effects. Based on the results, we proposed a method for modeling the trade-off of privacy preservation and activity recognition on low-resolution images.
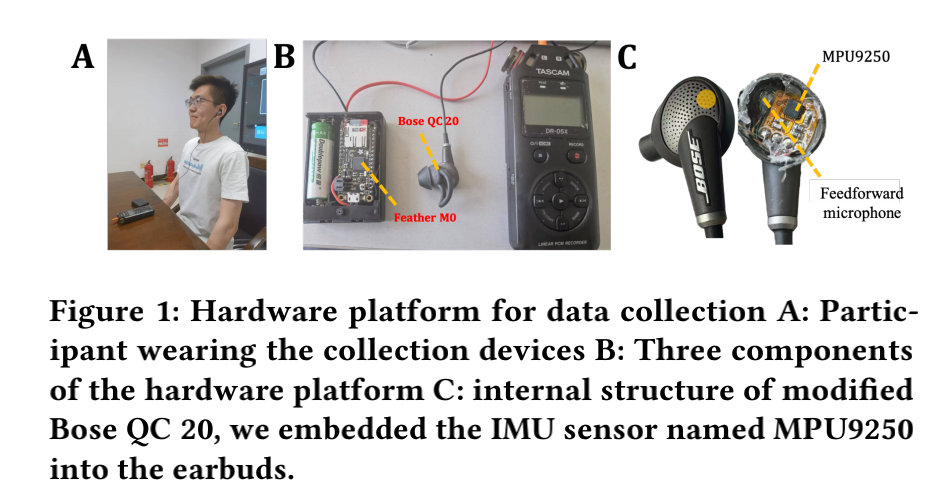
EarCough: Enabling Continuous Subject Cough Event Detection on Hearables
Abstract
Cough monitoring can enable new individual pulmonary health applications.Subject cough event detection is the foundation for continuous cough monitoring.Recently,the rapid growth in smart hearables has opened new opportunities for such needs. This pa-per proposes EarCough, which enables continuous subject cough event detection on edge computing hearables,by leveraging the always-on active noise cancellation (ANC)microphones. Specifi-cally,we proposed a lightweight end-to-end neural network model -EarCoughNet.To evaluate the effectiveness of our method,we constructed a synchronous motion and audio dataset through a user study. Results show that EarCough achieved an accuracy of 95.4%and an Fl-score of 92.9% with a space requirement of only 385 kB. We envision EarCough as a low-cost add-on for future hearables to enable continuous subject cough event detection.
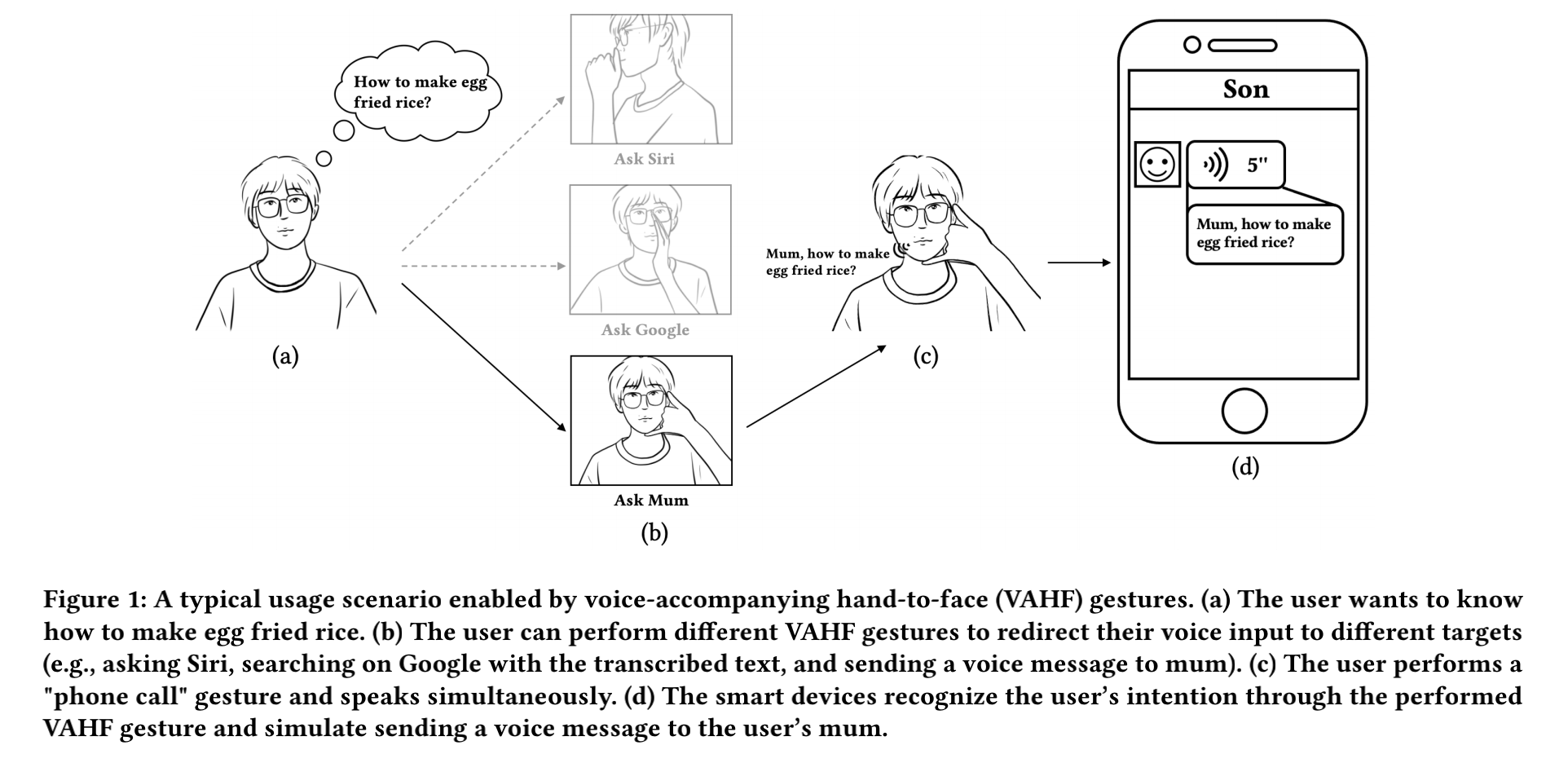
Enabling Voice-Accompanying Hand-to-Face Gesture Recognition with Cross-Device Sensing
Abstract
Gestures performed accompanying the voice are essential for voice interaction to convey complementary semantics for interaction purposes such as wake-up state and input modality. In this paper, we investigated voice-accompanying hand-to-face(VAHF)gestures for voice interaction. We targeted on hand-to-face gestures because such gestures relate closely to speech and yield significant acous-tic features (e.g., impeding voice propagation). We conducted a user study to explore the design space of VAHF gestures, where we first gathered candidate gestures and then applied a structural analysis to them in different dimensions(e.g.contact position and type), outputting a total of 8 VAHF gestures with good usability and least confusion. To facilitate VAHF gesture recognition, we proposed a novel cross-device sensing method that leverages het-erogeneous channels(vocal,ultrasound,and IMU) of data from commodity devices(earbuds,watches,and rings).Our recognition model achieved an accuracy of 97.3% for recognizing 3 gestures and 91.5%for recognizing 8 gestures(excluding the "empty"gesture). proving the high applicability. Quantitative analysis also shed light on the recognition capability of each sensor channel and their dif-ferent combinations. In the end, we illustrated the feasible use cases and their design principles to demonstrate the applicability of our system in various scenarios.
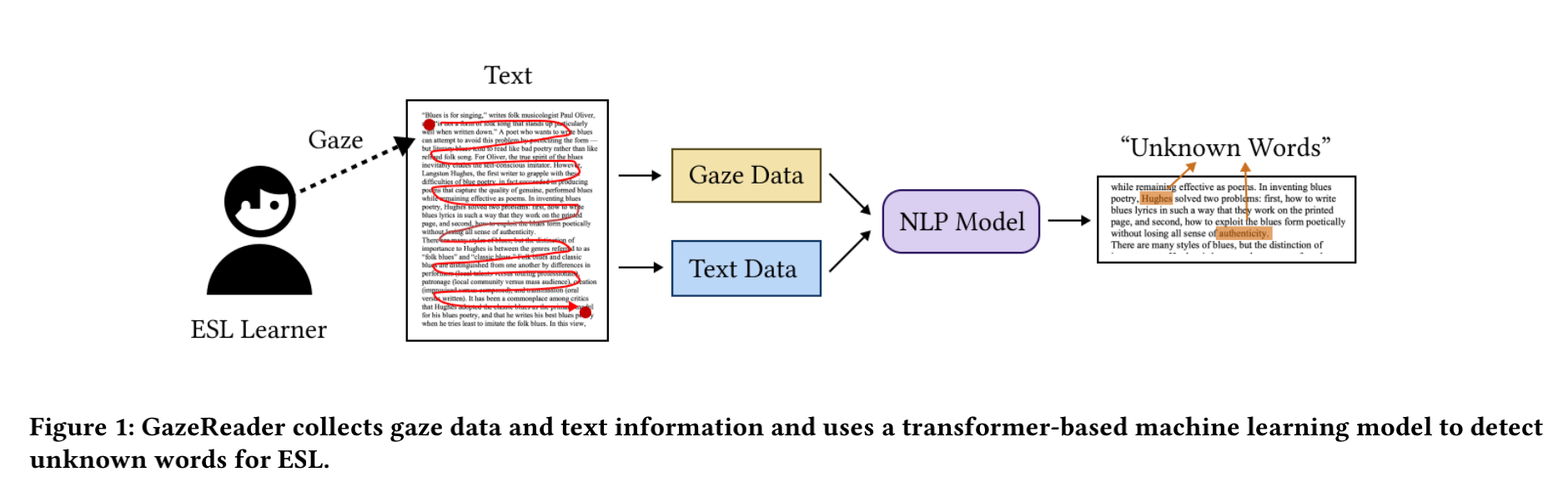
GazeReader: Detecting Unknown Word Using Webcam for English as a Second Language (ESL) Learners
Abstract
Automatic unknown word detection techniques can enable new ap-plications for assisting English as a Second Language(ESL)learners, thus improving their reading experiences. However,most modern unknown word detection methods require dedicated eye-tracking devices with high precision that are not easily accessible to end-users. In this work, we propose GazeReader, an unknown word detection method only using a webcam. GazeReader tracks the learner's gaze and then applies a transformer-based machine learn-ing model that encodes the text information to locate the unknown word. We applied knowledge enhancement including term fre-quency, part of speech, and named entity recognition to improve the performance. The user study indicates that the accuracy and F1-score of our method were 98.09% and 75.73%,respectively.Lastly, we explored the design scope for ESL reading and discussed the findings.
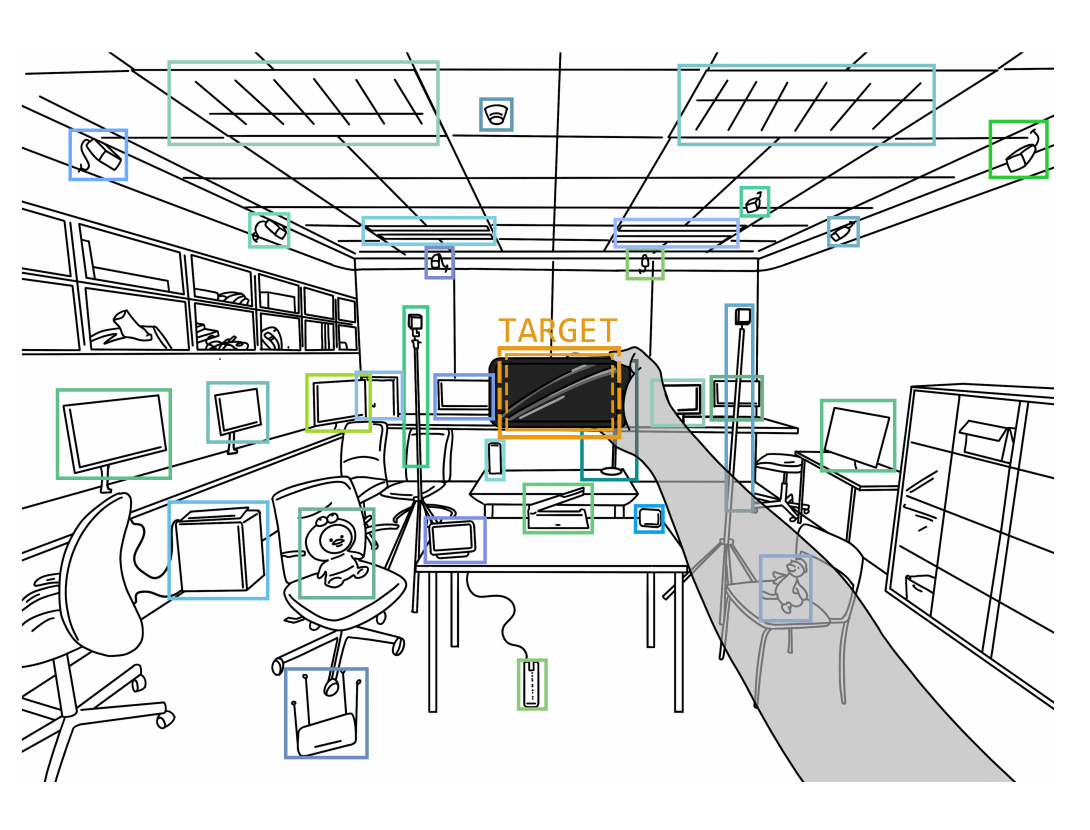
Selecting Real-World Objects via User-Perspective Phone
Abstract
Perceiving the region of interest (ROI) and target object by smart-phones from the user’s first-person perspective can enable diverse spatial interactions. In this paper, we propose a novel ROI input method and a target selecting method for smartphones by utilizing the user-perspective phone occlusion. This concept of turning the phone into real-world physical cursor benefits from the proprioception, gets rid of the constraint of camera preview, and allows users to rapidly and accurately select the target object. Meanwhile, our method can provide a resizable and rotatable rectangular ROI to disambiguate dense targets. We implemented the prototype system by positioning the user’s iris with the front camera and estimating the rectangular area blocked by the phone with the rear camera simultaneously, followed by a target prediction algorithm with the distance-weighted Jaccard index. We analyzed the behavioral models of using our method and evaluated our prototype system’s pointing accuracy and usability. Results showed that our method
is well-accepted by the users for its convenience, accuracy, and
efciency.