论文成果 / Publications
2026
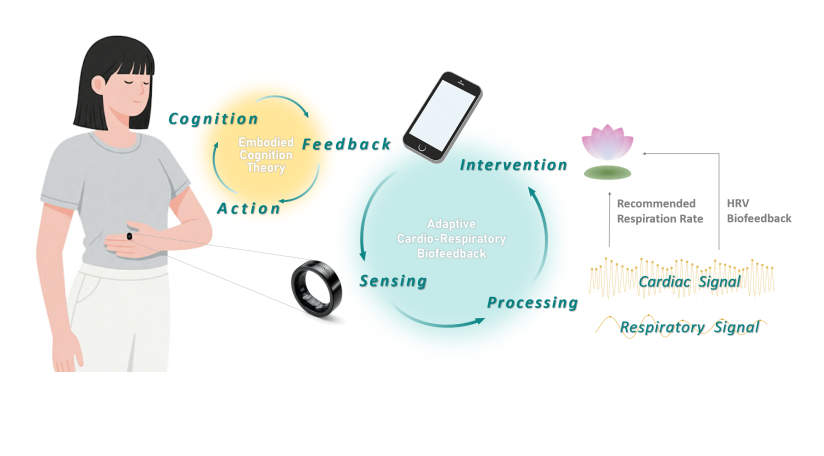
Enabling Adaptive Cardio-Respiratory Biofeedback Training on Ubiquitous Hand-Worn Devices
Abstract
We introduce an adaptive cardio-respiratory biofeedback system implemented on ubiquitous hand-worn devices such as smart watches and rings, enabling accessible and real-time physiological training outside clinical settings. Users place a hand on their abdomen to promote embodied awareness of breathing rhythms, while PPG and IMU sensors continuously capture cardio-respiratory signals. Unlike conventional open-loop biofeedback that delivers fixed breathing guidance irrespective of user response, our system employs a closed-loop adaptation: real-time physiological signals adjust breathing cues to optimize cardio-respiratory coupling, ensuring personalized training trajectories. This shift from static to adaptive guidance markedly improves user engagement and training efficacy. A user performance evaluation study further showed that adaptive biofeedback significantly boosts HRV, prolongs high-HRV states, and enhances user experience, demonstrating clear advantages over non-adaptive methods. Together, these findings position adaptive, hand-worn biofeedback as a promising approach for ubiquitous, user-centered mental health interventions.
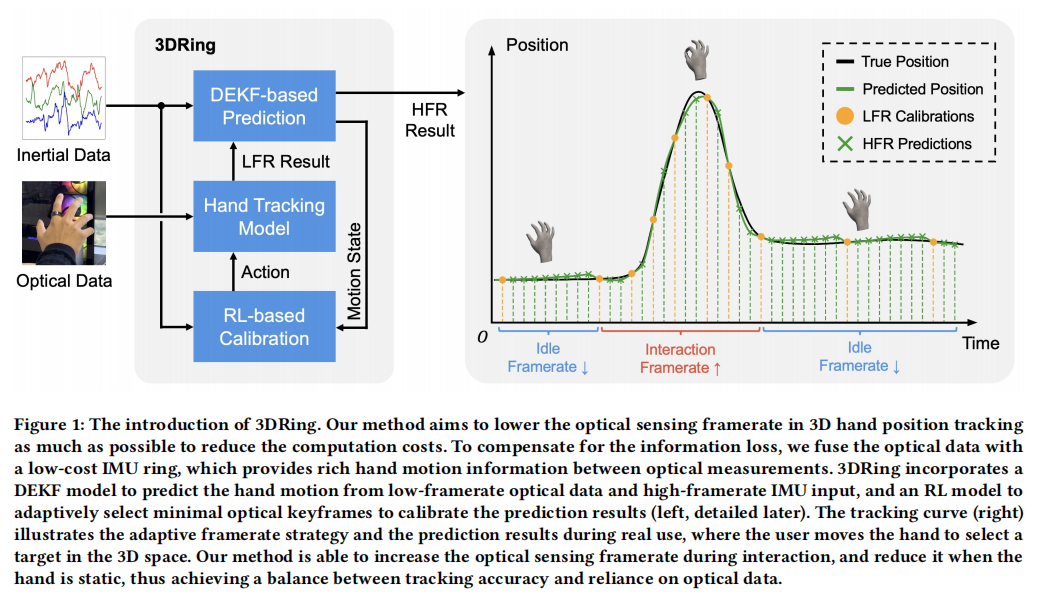
3DRing: Enabling Low-Cost 3D Hand Position Tracking by Fusing Inertial and Low-Framerate Optical Sensing
Abstract
Current mobile hand tracking systems primarily rely on highframerate (HFR) optical sensors to capture hand positions, resulting in high computational cost and limiting the applicability in end devices. We propose 3DRing, a 3D hand position tracking method that requires only low-framerate (LFR, <10 FPS) optical data and a single IMU ring. It consists of two stages: (1) a Deep Extended Kalman Filter module that predicts high-framerate hand positions from LFR optical measurements and a single IMU; (2) a Reinforcement Learning module that adaptively selects minimal keyframes for calibration, further reducing the average optical framerate. Using only 6.61 FPS optical data, 3DRing achieves an average real-time tracking error of 1.75 cm and an interaction efficiency of 86.0% in a 3D target selection task, compared to the 67 FPS hand tracking system of Meta Quest Pro, demonstrating a strong potential to reduce
the reliance on optical data in mobile hand tracking tasks.
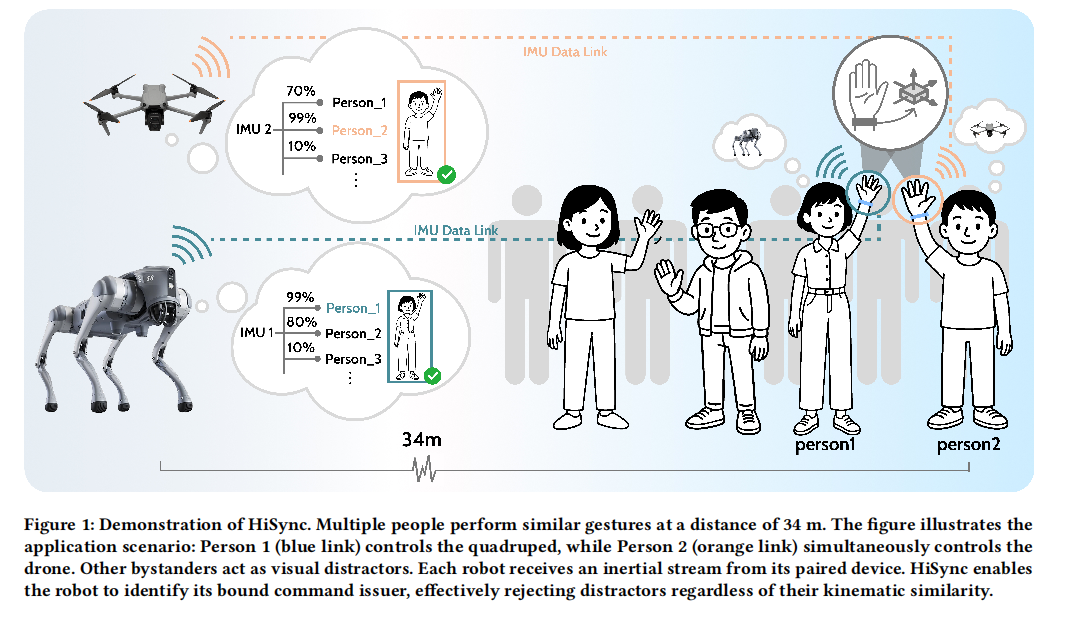
HiSync: Spatio-Temporally Aligning Hand Motion from Wearable IMU and On-Robot Camera for Command Source Identification in Long-Range HRI
Abstract
Long-range Human-Robot Interaction (HRI)remains underexplored. Within it, Command Source Identification (CSI) — determining who issued a command — is especially challenging due to multi-user and distance-induced sensor ambiguity. We introduce HiSync, an optical-inertial fusion framework that treats hand motion as binding cues by aligning robot-mounted camera optical flow with handworn IMU signals. We first elicit a user-defined (N=12) gesture set and collect a multimodal command gesture dataset (N=38) in longrange multi-user HRI scenarios. Next, HiSync extracts frequency domain hand motion features from both camera and IMU data,
and a learned CSINet denoises IMU readings, temporally aligns modalities, and performs distance-aware multi-window fusion to compute cross-modal similarity of subtle, natural gestures, enabling robust CSI. In three-person scenes up to 34 m, HiSync achieves 92.32% CSI accuracy, outperforming the prior SOTA by 48.44%.
HiSync is also validated on real-robot deployment. By making CSI reliable and natural, HiSync provides a practical primitive and design guidance for public-space HRI.
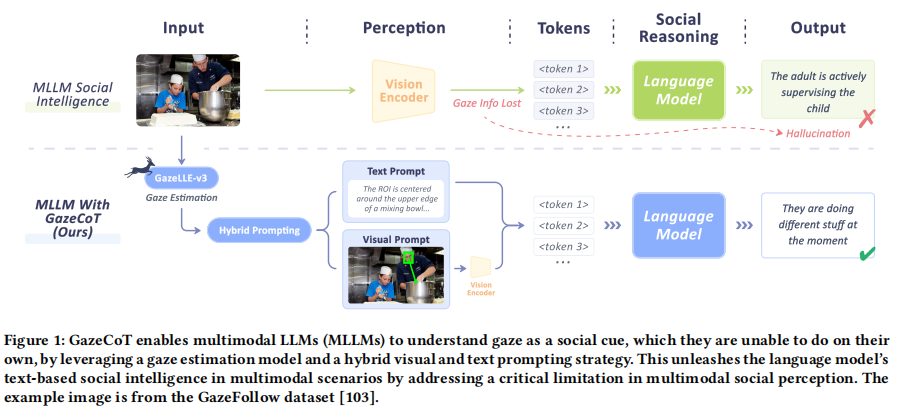
GazeCoT: Unleashing Social Intelligence in Multimodal LLMs With Gaze-Informed Chain-of-Thought Reasoning
Abstract
Social intelligence is vital for effective human-AI interaction. While LLMs demonstrate strong text-based social intelligence, the vision modality remains challenging due to the presence of non-verbal social cues. For example, gaze is the primary conveyor of social attention, yet it cannot be accurately perceived and understood by multimodal LLMs (MLLMs). Therefore, we propose GazeCoT, a pipeline using gaze estimation models to provide MLLMs with the attention of people in images or videos. The gaze information is provided as visual and text prompts compiled into a structured context
to support MLLM social reasoning. Benchmark evaluation confirms that GazeCoT enhances MLLMs’ social intelligence by improving gaze perception. A user study in a challenging application involving parent-child interactions demonstrates that GazeCoT improves perceived explainability and trustworthiness by aligning MLLM social perception and social reasoning with human norms. We hope that GazeCoT, a versatile plug-and-play pipeline, can enable socially aware, MLLM-based HCI applications.
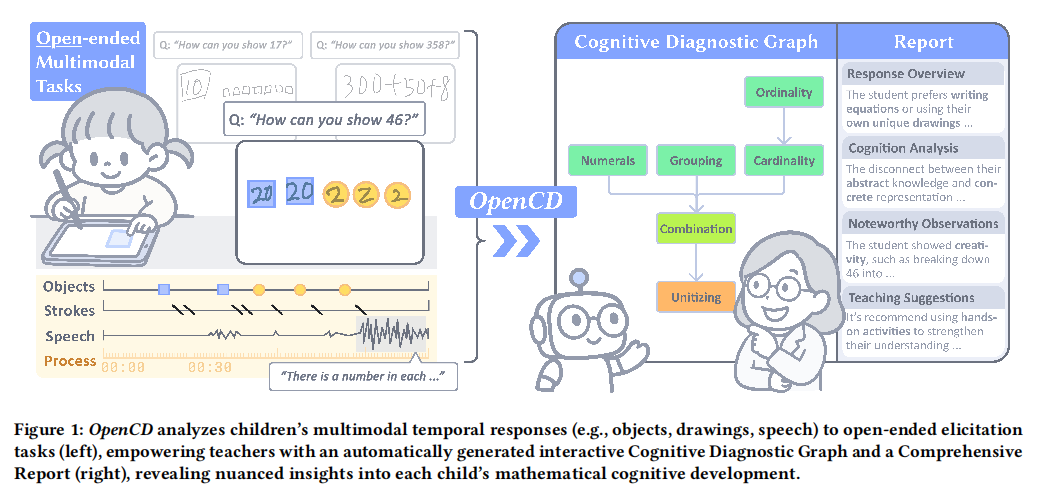
OpenCD: Empowering Diagnosis of Children’s Mathematical Cognition through Open-ended Multimodal Tasks
Abstract
Assessing children’s cognitive development in early mathematics is vital for effective teaching. Compared to closed-ended questions, which may fail to capture nuanced developmental spectrum, openended elicitation tasks(e.g., asking studentsto manipulate objects or draw to represent numbers) serve as a promising approach to reveal deeper cognitive processes. However, their diverse and unstructured nature makes systematic analysis challenging for teachers. We present OpenCD, a teacher-facing system that automatically analyzes multimodal student responses to capture individualized insights. Based on Evidence-Centered Design, it combines Vision Language Models (VLMs) and expert models to generate interactive diagnostic graphs and reports with traceability back to behavioral evidence. In our two-part evaluation, a validation study found 90.3% of the system’s diagnoses “completely reasonable,” and a user study showed that OpenCD reduced teachers’ analysis burden and enhanced their insights into student thinking. Our work contributes to scalable process-based assessment for mathematical literacy.
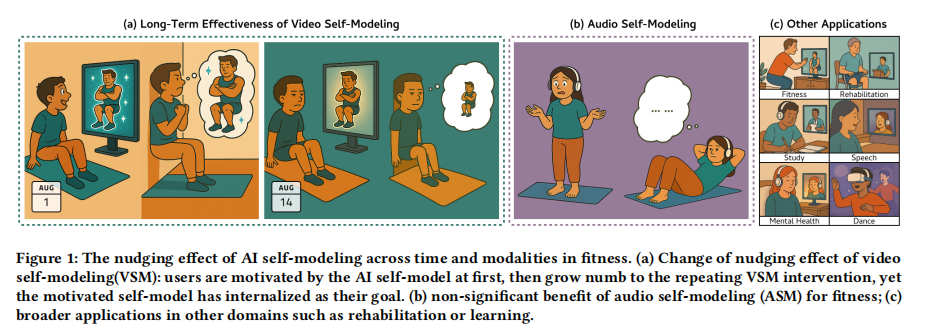
Does Personalized Nudging Wear Off? A Longitudinal Study of AI Self-Modeling for Behavioral Engagement
Abstract
Sustaining the effectiveness of behavior change technologies remains a key challenge. AI self-modeling, which generates personalized portrayals of one’s ideal self, has shown promise for motivating behavior change, yet prior work largely examines short-term effects. We present one of the first longitudinal evaluations of AI self-modeling in fitness engagement through a two-stage empirical study. A 1-week, three-arm experiment (visual self-modeling (VSM), auditory self-modeling (ASM), Control; N=28) revealed that VSM drove initial performance gains, while ASM showed no significan effects. A subsequent 4-week study (VSM vs. Control; N=31) demonstrated that VSM sustained higher performance levels but exhibited
diminishing improvement rates after two weeks. Interviews uncovered a catalyst effect that fostered early motivation through clear, attainable goals, followed by habituation and internalization which stabilized performance. These findings highlight the temporal dynamics of personalized nudging and inform the design of behavior change technologies for long-term engagement.
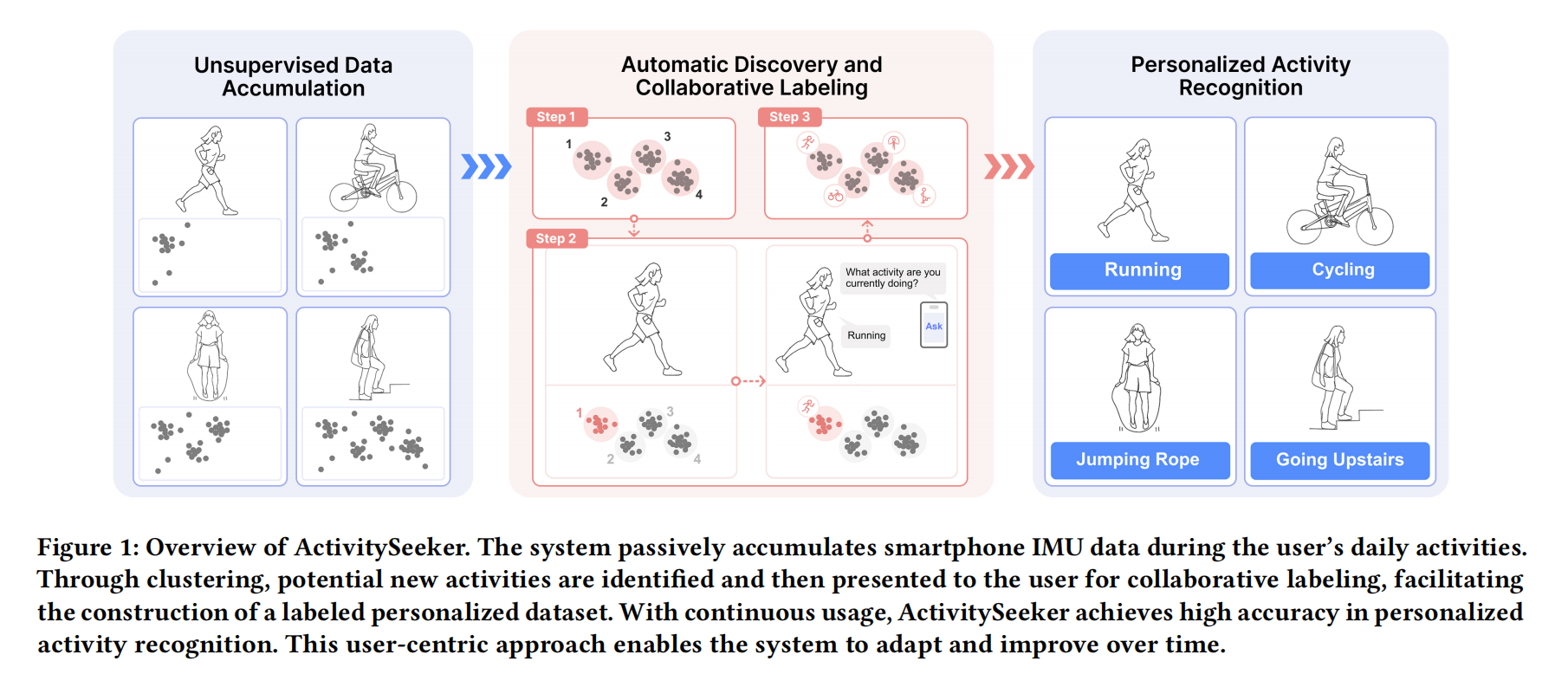
ActivitySeeker: Towards Collaborative Personalized Human Activity Discovery and Recognition on Smartphones
Abstract
Smartphones provide an attractive yet challenging platform for human activity recognition (HAR). They are ubiquitous, but also limit the input of HAR systems to a single IMU. These systems are also challenged by the inherent diversity of human activities and varying phone placement on the user’s body. This results in traditional smartphone HAR systems having limited personalization potential or imposing a high user burden. We propose ActivitySeeker, a personalized smartphone HAR system that combines self-supervised activity discovery and low-burden user interaction to collaboratively label IMU data and adapt HAR models to individual users on-device through transfer learning. We evaluated ActivitySeeker through simulated online learning and in-the-wild user experiments, where it discovered 95.5% of personal activity types and achieved high recognition accuracy (93.3%) while maintaining a positive user experience. Leveraging the synergy between
user and smartphone, ActivitySeeker opens up new possibilities
for HAR-based applications like fitness, health and personalized
recommendation.
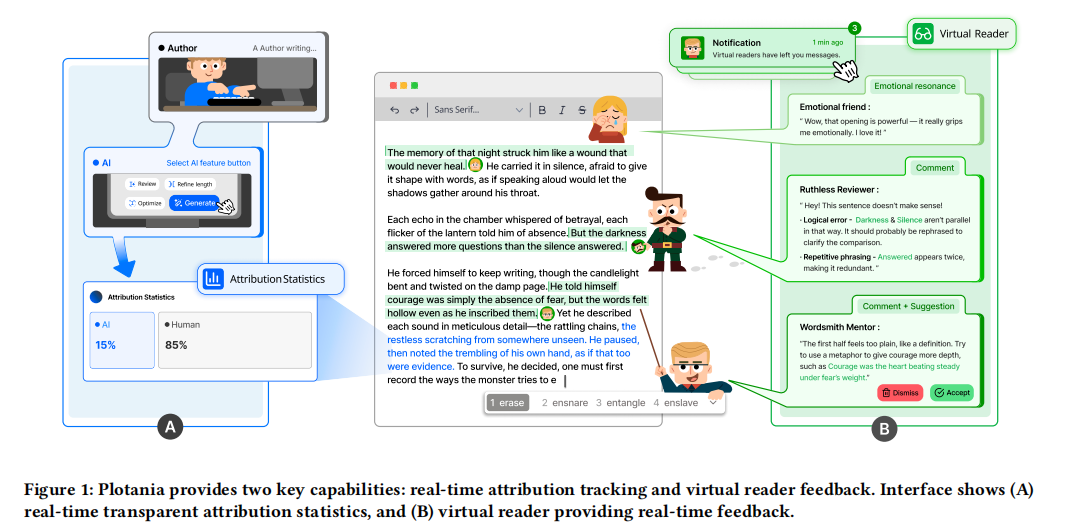
Plotania: Exploring Transparency Trade-offs in AI Co-Writing Through Virtual Readers and Transparent Attribution
Abstract
Current AI writing tools aim to enhance authorial capacity yet often diminish authorial control and lack timely audience feedback. Through a formative study with fiction authors (N=10), we uncovered two critical tensions in human–AI co-writing: balancing AI scaffolding with authorial ownership, and the absence of contextual audience perspectives that shape storytelling during drafting. Guided by these insights, we designed Plotania, a co-writing system that combines proactive virtual readers offering real-time audience reactions with transparent attribution layers. A controlled study
(N=20) revealed complex and counterintuitive effects: virtual reader feedback increased audience awareness but decreased perceived creative agency, transforming individual authorship into collaborative performance. Transparent attribution raised awareness of AI contributions but triggered identity anxiety and reduced AI usage. These findings reveal fundamental trade-offs in transparency design. We contribute design principles for “agency-preserving transparency” that balance information provision with creative empowerment, informing future transparency design in human-AI creative collaboration.

Proactive AI as a Catalyst for Creativity? Balancing Human Agency and AI Contribution in Collaborative Story Writing
Abstract
Large Language Models (LLMs) hold promise in supporting creative writing, yet the role of proactive AI in collaborative writing remains underexplored due to concerns around human agency and disruption. To investigate effective strategies for proactive AI support, we conducted a Wizard-of-Oz study simulating two suggestion styles: intrusive suggestions (next-sentence completions) and non-intrusive suggestions (exploratory proposals), where participants completed two story outlining tasks under each style, receiving real-time proactive suggestions from a human wizard acting as the AI. Both quantitative and qualitative results show that proactive AI can enhance creativity and accelerate writing.
However, we observed a trade-off between AI involvement and perceived human agency. This trade-off was moderated by how strongly AI stimulated users–greater inspiration led to stronger perceived agency even under high AI involvement. Based on wizards’ behavior, we offer guidance on suggestion style and timing to better balance creativity and agency for future proactive AI writing systems.