论文成果 / Publications
2026

TraceRing: Touchpad-like Pointing with a Single IMU Ring through Personalized Learning
Abstract
Achieving touchpad-like pointing with a single IMU ring is highly desirable for portable and wearable interaction,yet challenging due to incomplete motion data and significant user variability. We present TraceRing, a finger-worn IMU system that enables precise two-dimensional cursor control. To address the limitations of generic end-to-end models, we propose a personalized training framework that learns user-specific representations through joint multi-task and contrastive learning, while dynamically selecting the most suitable expert model.This approach enables personalization without requiring per-user fine-tuning, and reduces velocity prediction error by 33.9%over state-of-the-art baselines. Furthermore, a real-time study shows it delivers speed and accuracy far exceeding those of AirMouse(2.26s v.s.3.01s in average task completion time). These results demonstrate TraceRing as a portable and comfortable altermative for mobile computing and AR interaction applications.
2025
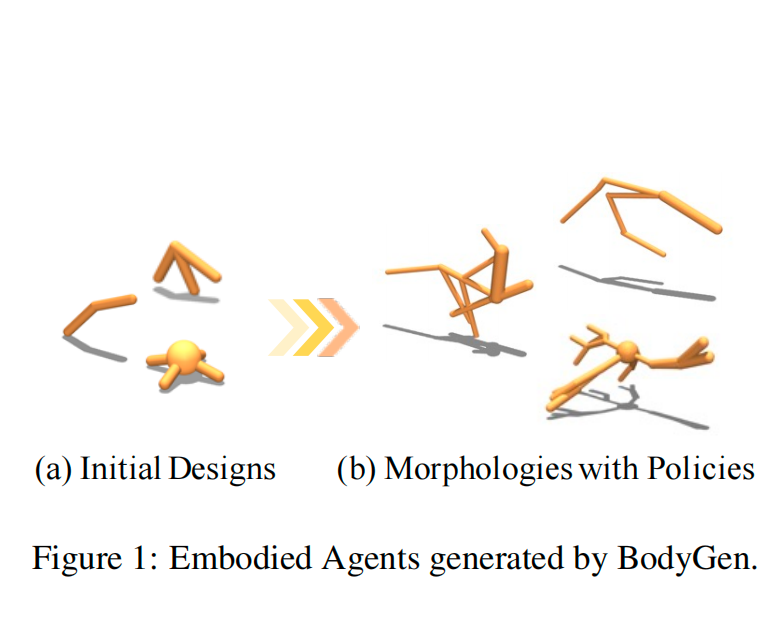
BodyGen: Advancing Towards Efficient Embodiment Co-Design
Abstract
Embodiment co-design aims to optimize a robot's morphology and control policy simultaneously. While prior work has demonstrated its potential for generating environment-adaptive robots, this field still faces persistent challenges in optimization efficiency due to the (i) combinatorial nature of morphological search spaces and (ii) intricate dependencies between morphology and control. We prove that the ineffective morphology representation and unbalanced reward signals between the design and control stages are key obstacles to efficiency. To advance towards efficient embodiment co-design, we propose BodyGen, which utilizes (1) topology-aware self-attention for both design and control, enabling efficient morphology representation with lightweight model sizes; (2) a temporal credit assignment mechanism that ensures balanced reward signals for optimization. With our findings, BodyGen achieves an average 60.03% performance improvement against state-of-the-art baselines. We provide codes and more results on the website: https://genesisorigin.github.io.
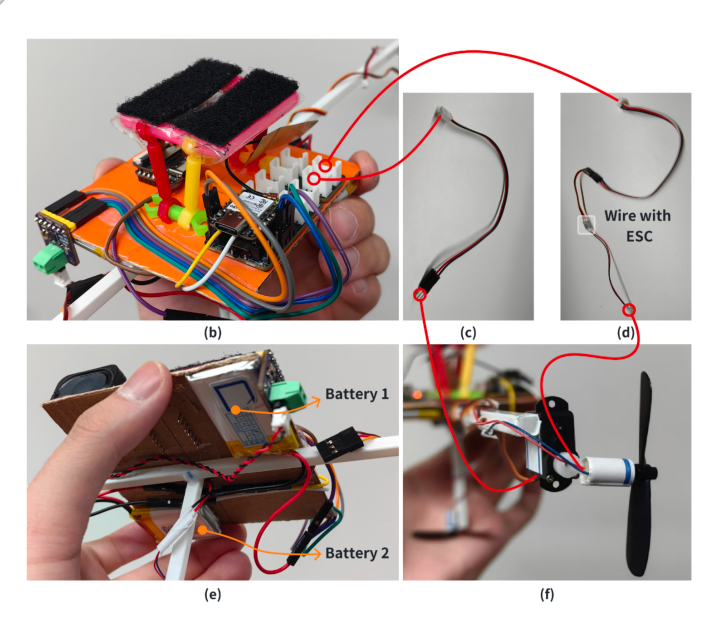
Understanding Users’ Perceptions and Expectations toward a Social Balloon Robot via an Exploratory Study
Abstract
We are witnessing a new epoch in embodied social agents. Most of the work has focused on ground or desktop robots that enjoy technical maturity and rich social channels but are often limited by terrain. Drones, which enable spatial mobility, currently face issues with safety and proximity. This paper explores a social balloon robot as a viable alternative that combines these advantages and alleviates limitations. To this end, we developed a hardware prototype named BalloonBot that integrates various devices for social functioning and a helium balloon. We conducted an exploratory lab study on users’ perceptions and expectations about its demonstrated interactions and functions. Our results show promise in using such a robot as another form of socially embodied agent. We highlight its unique mobile and approachable characteristics that harvest novel user experiences and outline factors that should be considered before its broad applications.
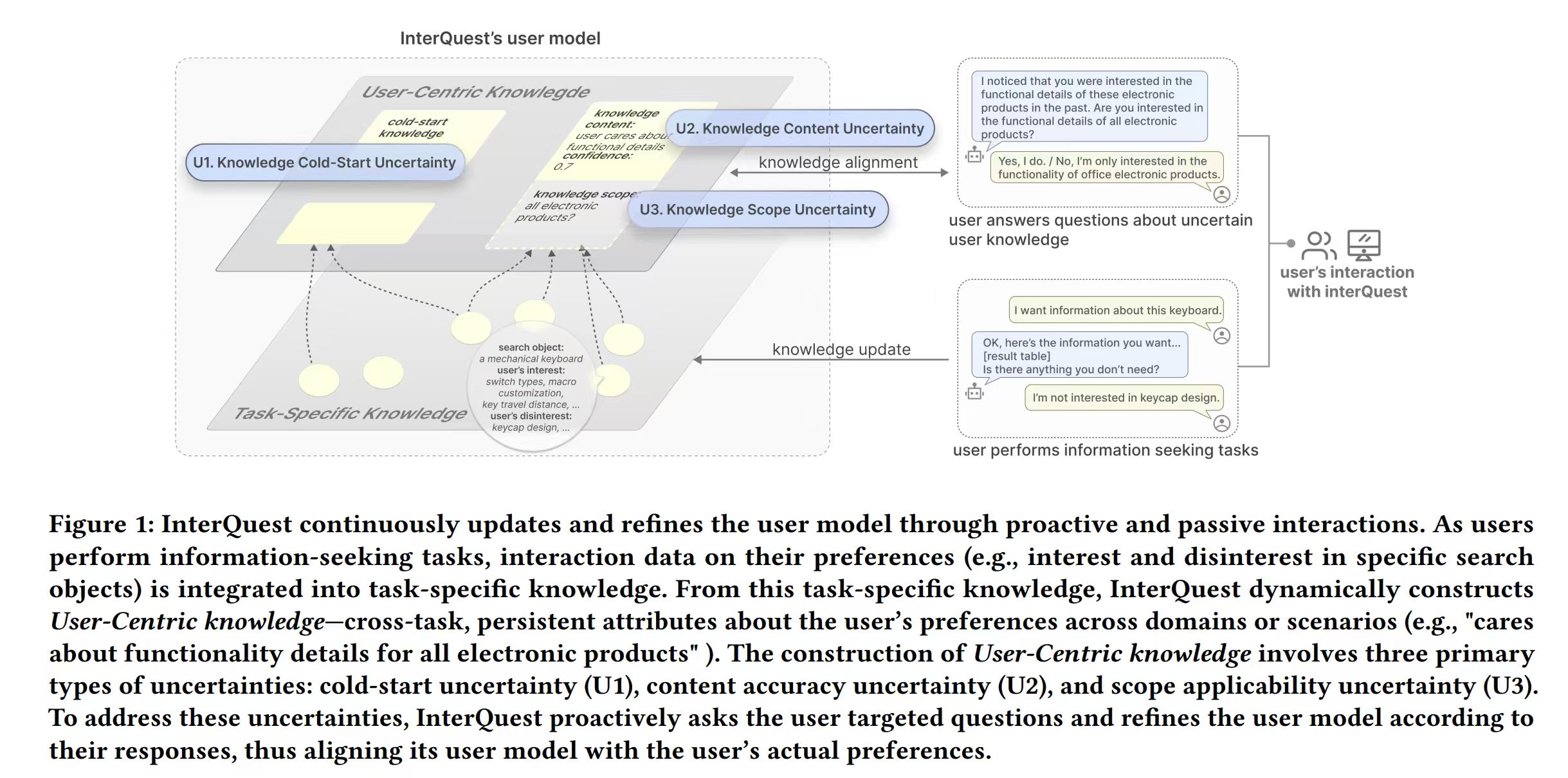
InterQuest: A Mixed-Initiative Framework for Dynamic User Interest Modeling in Conversational Search
Abstract
In online information-seeking tasks (e.g., for products and restaurants), users seek information that aligns with their individual preferences to make informed decisions. However, existing systems often struggle to infer users’ implicit interests—unstated yet essential preference factors that directly impact decision quality. Our formative study reveals that User-Centric Knowledge—cross-task persistent preference attributes of users (e.g., “user cares about functionality details for electronics”)—serves as a key indicator for resolving users’ implicit interests. However, constructing such knowledge from task-specific data alone is insufficient due to three types of uncertainties—cold-start limitation, content accuracy, and scope applicability—which require user-provided information for knowledge alignment. Based on these insights, we present InterQuest, an LLM-based conversational search agent that dynamically models user interests. InterQuest combines two strategies: (1) Dynamic User Knowledge Modeling, which infers and adjusts the content and scope of User-Centric Knowledge, and (2) Uncertainty-Driven Questioning, where InterQuest proactively asks questions to resolve knowledge uncertainties. A user study with 18 participants demonstrates that InterQuest outperforms the baselines in user interest inference, accuracy of user knowledge modeling, and the overall information-seeking experience. Additionally, our findings provide valuable design implications for improving mixed-initiative user modeling in future systems.

GTR: Guided Thought Reinforcement Prevents Thought Collapse in RL-based VLM Agent Training
Abstract
Reinforcement learning with verifiable outcome rewards (RLVR) has effectively scaled up chain-of-thought (CoT) reasoning in large language models (LLMs). Yet, its efficacy in training vision-language model (VLM) agents for goal-directed action reasoning in visual environments is less established. This work investigates this problem through extensive experiments on complex card games, such as 24 points, and embodied tasks from ALFWorld. We find that when rewards are based solely on action outcomes, RL fails to incentivize CoT reasoning in VLMs, instead leading to a phenomenon we termed thought collapse, characterized by a rapid loss of diversity in the agent’s thoughts, stateirrelevant and incomplete reasoning, and subsequent invalid actions, resulting in negative rewards. To counteract thought collapse, we highlight the necessity of process guidance and propose an automated corrector that evaluates and refines
the agent’s reasoning at each RL step. This simple and scalable GTR (Guided Thought Reinforcement) framework trains reasoning and action simultaneously without the need for dense, per-step human labeling. Our experiments demonstrate that GTR significantly enhances the performance and generalization of the LLaVA-7B model across various visual environments, achieving 3-5 times higher task success rates compared to SoTA models with notably smaller model sizes
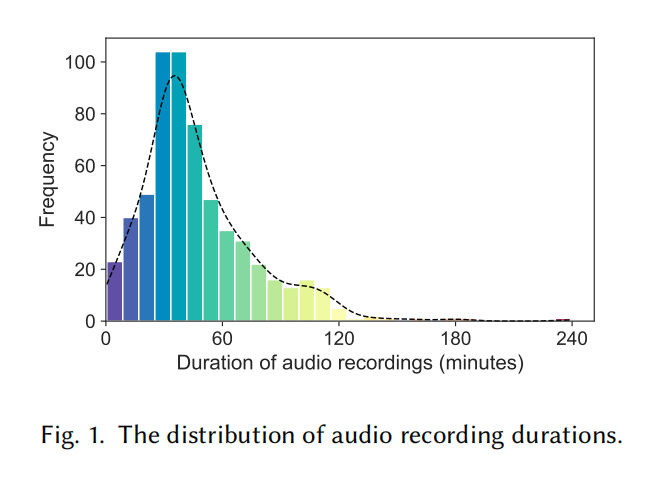
The Homework Wars: Exploring Emotions, Behaviours, and Conflicts in Parent-Child Homework Interactions
Abstract
Parental involvement in homework is a crucial aspect of family education, but it often triggers emotional strain and conflicts. Despite growing concern over its impact on family well-being, prior research has lacked access to fine-grained, real-time dynamics of these interactions. To bridge this gap, we present a framework that leverages naturalistic parent-child interaction data and large language models (LLMs) to analyse homework conversations at scale. In a four-week in situ study with 78 Chinese families, we collected 475 hours of audio recordings and accompanying daily surveys, capturing 602 homework sessions in everyday home settings. Our LLM-based pipeline reliably extracted and categorised parental behaviours and conflict patterns from transcribed conversations, achieving high agreement with expert annotations. The analysis revealed significant emotional shifts in parents before and after homework, 18 recurring parental behaviours and seven common conflict types, with Knowledge Conflict being the most frequent. Notably, even well-intentioned behaviours were significantly positively correlated with specific conflicts. This work advances ubiquitous computing methods for studying complex family dynamics and offers empirical insights to enrich family education theory and inform more effective parenting strategies and interventions in the future.
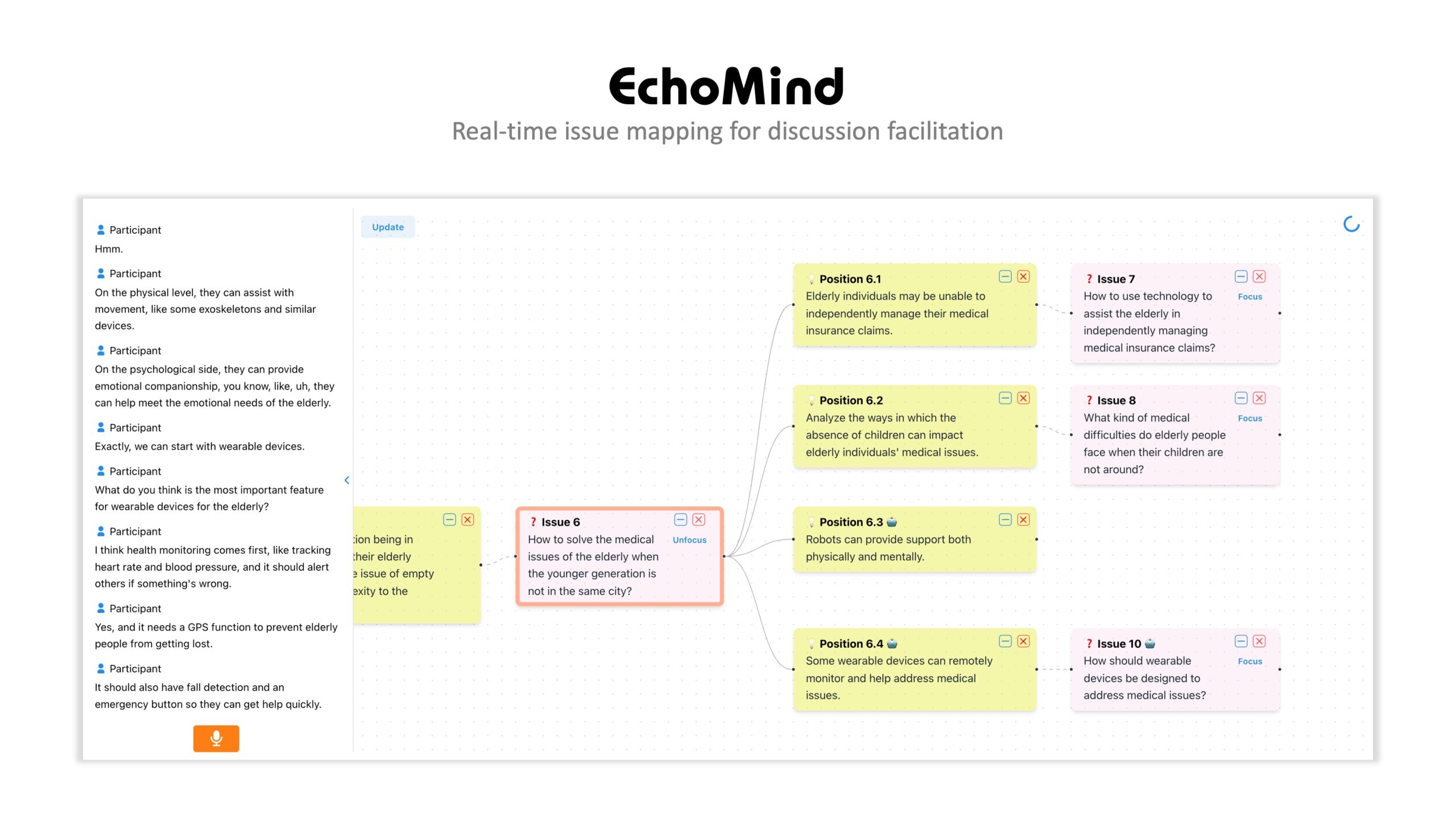
EchoMind: Supporting Real-time Complex Problem Discussions through Human-AI Collaborative Facilitation
Abstract
Teams often engage in group discussions to leverage collective intelligence when solving complex problems. However, in real-time discussions, such as face-to-face meetings, participants frequently struggle with managing diverse perspectives and structuring content, which can lead to unproductive outcomes like forgetfulness and off-topic conversations. Through a formative study, we explores a human-AI collaborative facilitation approach, where AI assists in establishing a shared knowledge framework to provide a guiding foundation. We present EchoMind, a system that visualizes discussion knowledge through real-time issue mapping. EchoMind empowers participants to maintain focus on specific issues, review key ideas or thoughts, and collaboratively
expand the discussion. The system leverages large language models (LLMs) to dynamically organize dialogues into nodes based on the current context recorded on the map. Our user study with four teams (N=16) reveals that EchoMind helps clarify discussion objectives, trace knowledge pathways, and enhance overall productivity. We also discuss the design implications for human-AI collaborative facilitation and the potential of shared knowledge visualization to transform group dynamics in future collaborations.
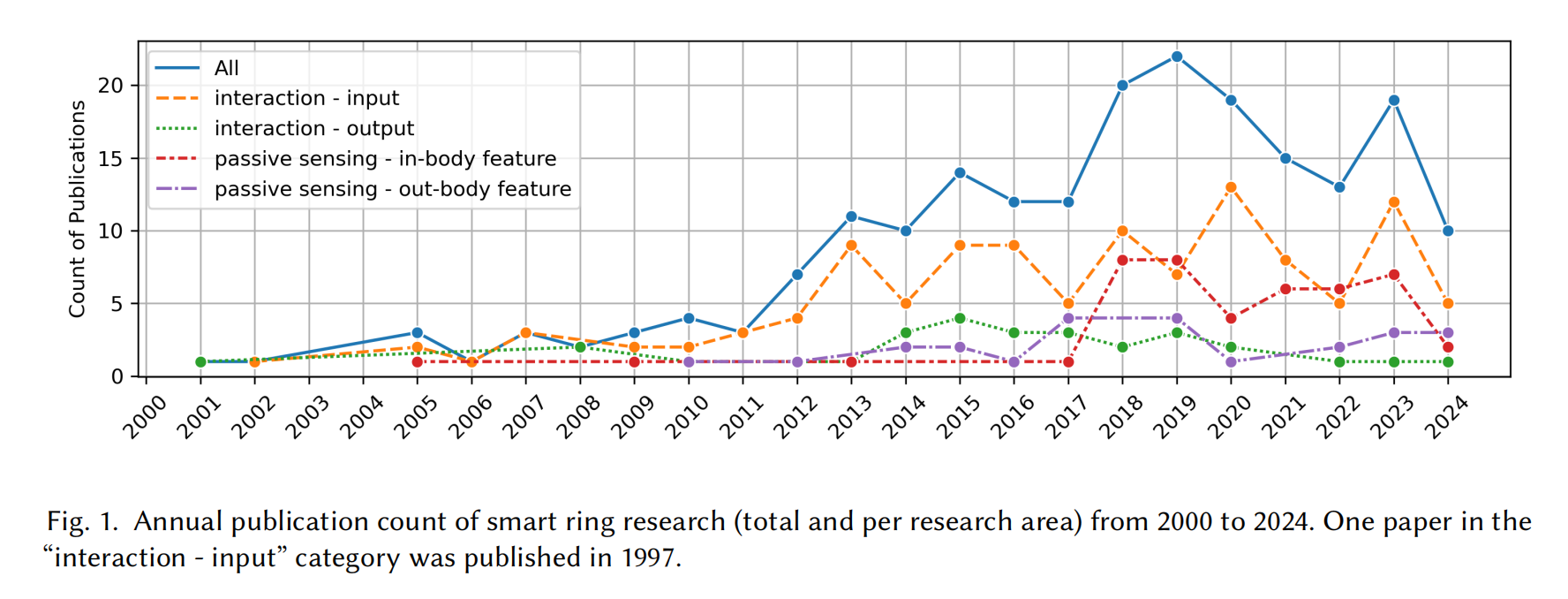
Computing with Smart Rings: A Systematic Literature Review
Abstract
A smart ring is a wearable electronic device in the form of a ring that incorporates diverse sensors and computing technologies to perform a variety of functions. Designed for use with fingers, smart rings are capable of sensing more subtle and abundant hand movements, thus making them a good platform for interaction. Meanwhile, fingers are abundant with blood vessels and nerve endings and accustomed to wearing rings, providing an ideal site for continuous health monitoring through smart rings, which combine comfort with the ability to capture vital biometric data, making them suitable for all-day wear. We collected in total of 206 smart ring-related publications and conducted a systematic literature review. We provide a taxonomy
regarding the sensing and feedback modalities, applications, and phenomena. We review and categorize these literatures into four main areas: (1) interaction - input, (2) interaction - output, (3) passive sensing - in body feature, (4) passive sensing - out body activity. This comprehensive review highlights the current advancements within the field of smart ring and identifies potential areas for future research.
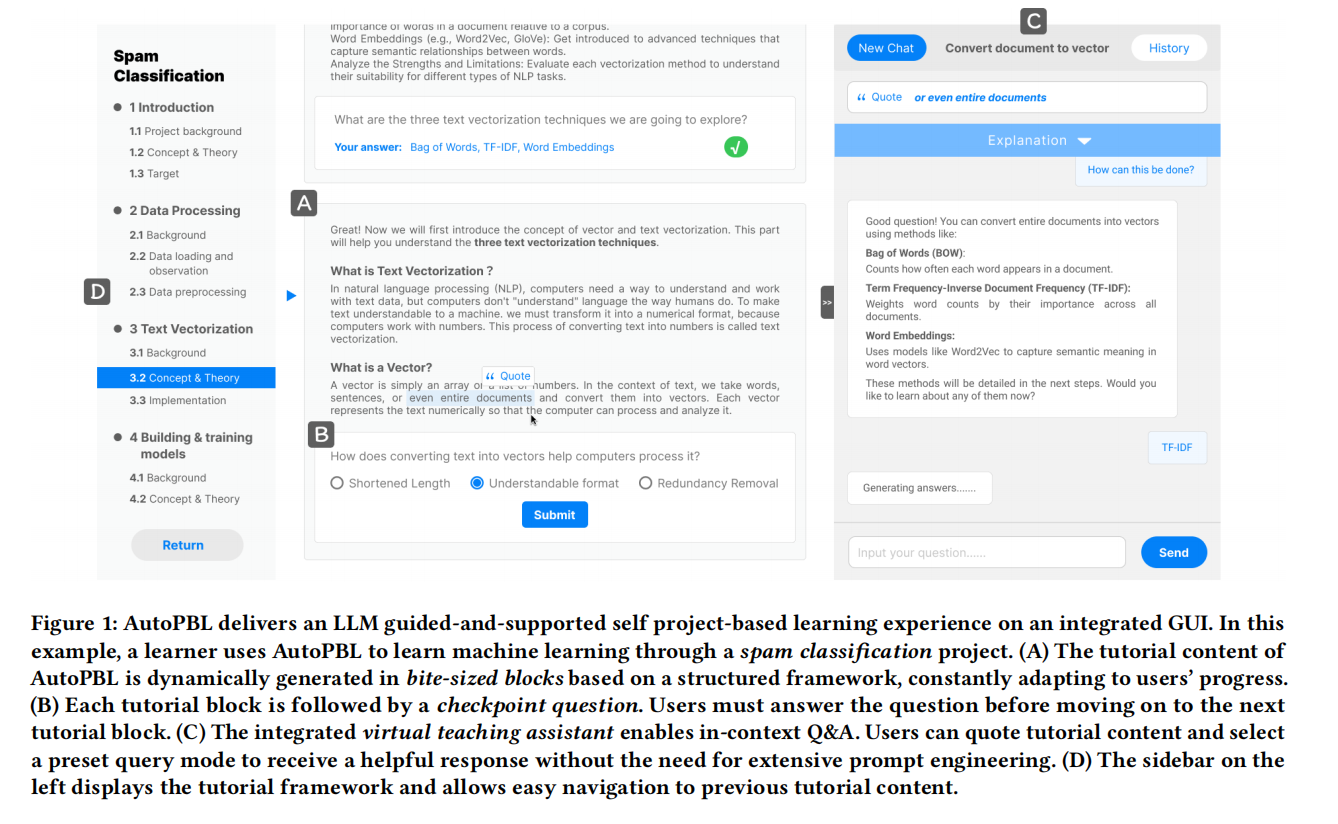
AutoPBL: An LLM-powered Platform to Guide and Support Individual Learners Through Self Project-based Learning
Abstract
Self project-based learning (SPBL) is a popular learning style where learners follow tutorials and build projects by themselves. SPBL combines project-based learning’s benefit of being engaging and
effective with the flexibility of self-learning. However, insufficient guidance and support during SPBL may lead to unsatisfactory learning experiences and outcomes. While LLM chatbots (e.g., ChatGPT)
could potentially serve as SPBL tutors, we have yet to see an SPBL platform with responsible and systematic LLM integration. To address this gap, we present AutoPBL, an interactive learning platform for SPBL learners. We examined human PBL tutors’ roles through formative interviews to inform our design. AutoPBL features an LLM-guided learning process with checkpoint questions and incontext Q&A. In a user study where 29 beginners learned machine learning through entry-level projects, we found that AutoPBL effectively improves learning outcomes and elicits better learning behavior and metacognition by clarifying current priorities and providing timely assistance.