论文成果 / Publications
2022
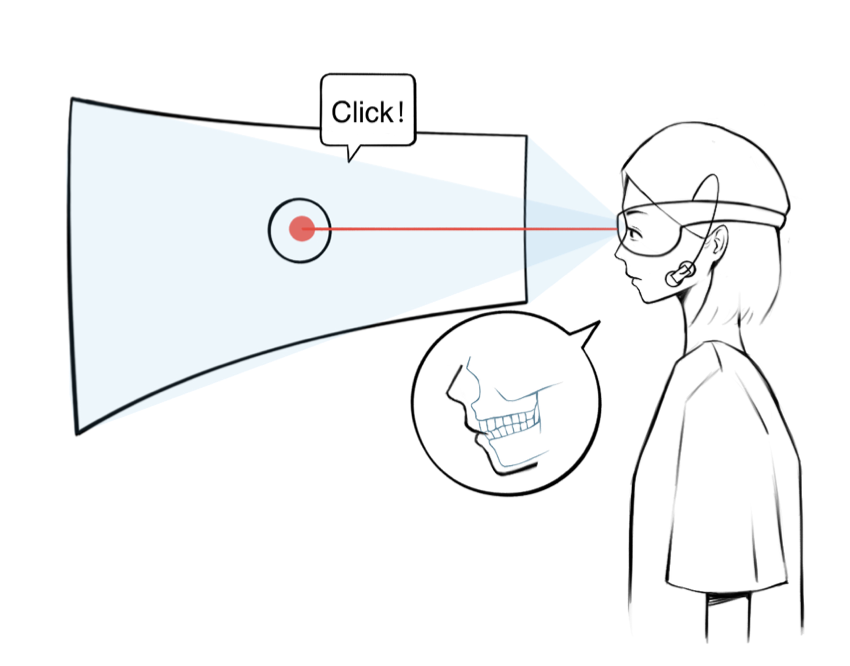
ClenchClick: Hands-Free Target Selection Method Leveraging Teeth-Clench for Augmented Reality
Abstract
We propose to explore teeth-clenching-based target selectionin Augmented Reality (AR), as the subtlety in the interaction can be beneficial to applications occupying the user's hand orthat are sensitive to social norms. To support the investigation, we implemented an EMG-based teeth-clenching detectionsystem (ClenchClick), where we adopted customized thresholds for different users. We first explored and compared the potential interaction design leveraging head movements and teeth clenching in combination. We finalized the interaction to take the form of a Point-and-Click manner with clenches as the confirmation mechanism. We evaluated the taskload and performance of ClenchClick by comparing it with two baseline methods in target selection tasks.Results showed that ClenchClick outperformed hand gestures in workload, physical load, accuracy and speed, and outperformed dwell in work load andl temporal load. Lastly, through user studies, we demonstrated the advantage of ClenchClick in real-world tasks, including efficient and accurate hands-free target selection, natural and unobtrusive interaction in public, and robust head gesture input.
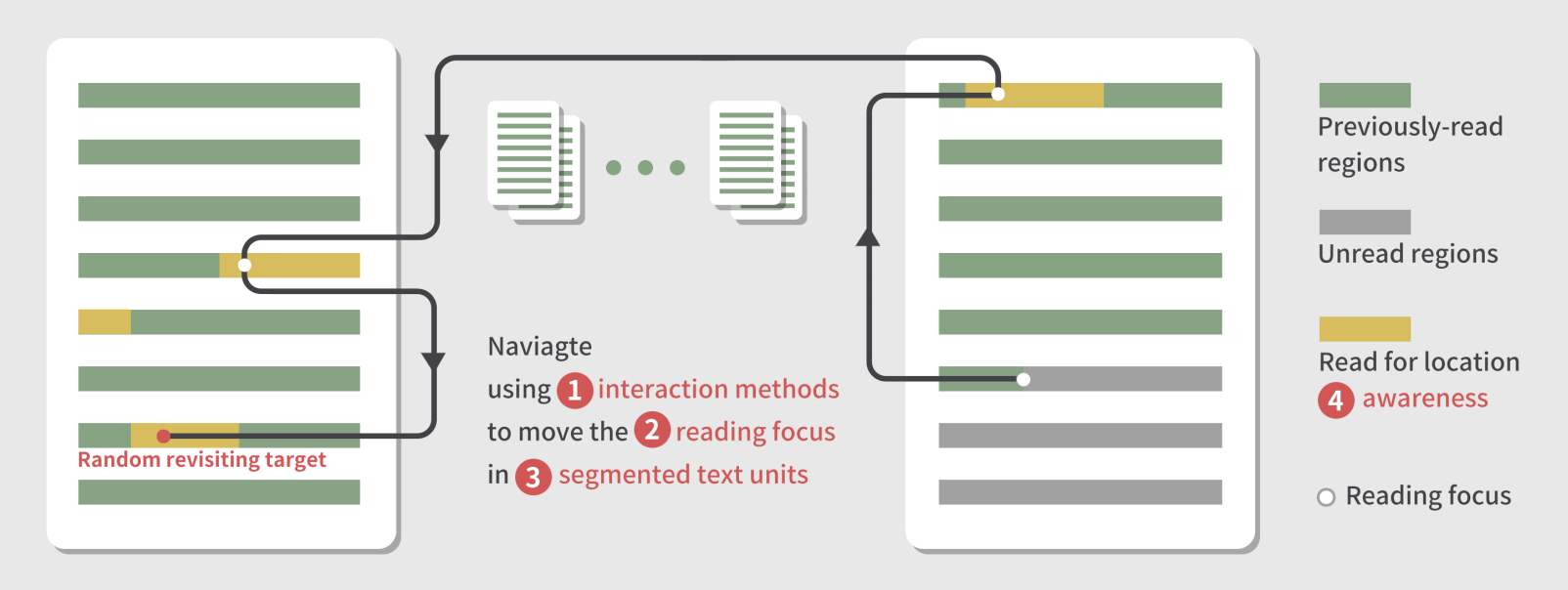
Enhancing Revisitation in Touchscreen Reading for Visually Impaired People with Semantic Navigation Design
Abstract
Revisitation, the process of non-linearly returning to previously visited regions, is an important task in academic reading. However, listening to content on mobile phones via a screen reeader fails to support eyes-free revisiting due to its linear audio stream, ineffective text organization, and inaccessible interaction. To enhance the efficiency and experience of eyes-free revisiting, we identified visually impaired people's behaviorsand difficulties during text revisiting through a survey (N=37) and an observation study (N=12). We proposed a series of desiign guidelines targeting high precision, high flexibility, and low workload in interaction, and iteratively designed and deyveloped a reading prototype application. Our implementation supports dynamic text structure and is supplemented by bothlinear and non-linear layered text navigation. The evaluation results(N=8)show that compared to existing methods, our prototype improves the clarity of text understanding and fluency of revisiting with reduced workload.
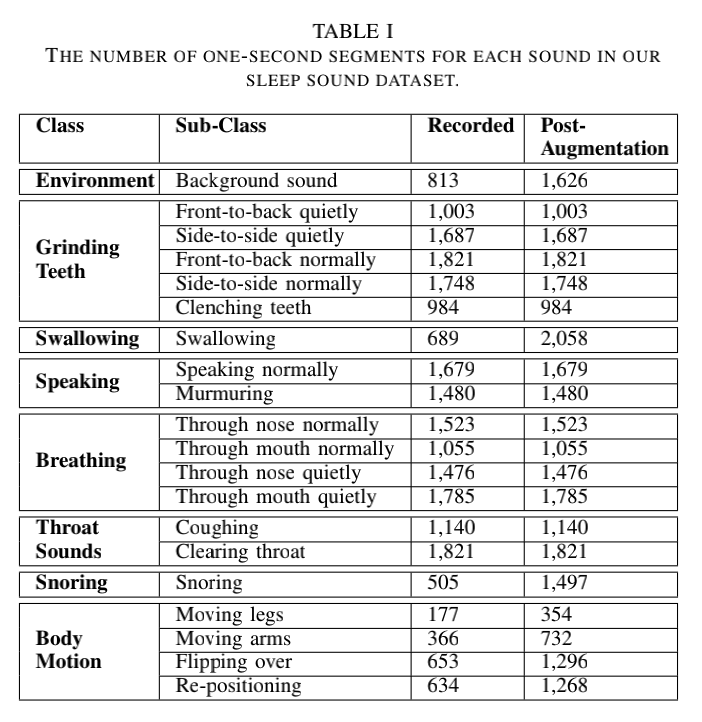
Sleep Sound Classification Using ANC-Enabled Earbuds
Abstract
Standard sleep quality assessment methods require custom hardware and professional observation, limiting the diagnosis of sleep disorders to specialized sleep clinics. In this work, we leverage the internal and external microphones present in active noise-cancelling earbuds to distinguish sounds associated with poor or disordered sleep, thereby enabling at-home continuous sleep sound monitoring. The sleep sounds our system is able to recognize include, but are not limited to, snoring. teeth grinding, and restless movement. We analyze the resulting dual-channel audio using a lightweight deep learning model built around a variation of the temporal shift module that has been optimized for audio. The model was designed to have a low memory and computational footprint, making it suitable to be run on a smartphone or the earbuds themselves. We evaluate our approach on a dataset of 8 sound categories generated from 20 participants. We achieve a classification accuracy of 91.0% and an F1-score of 0.845.
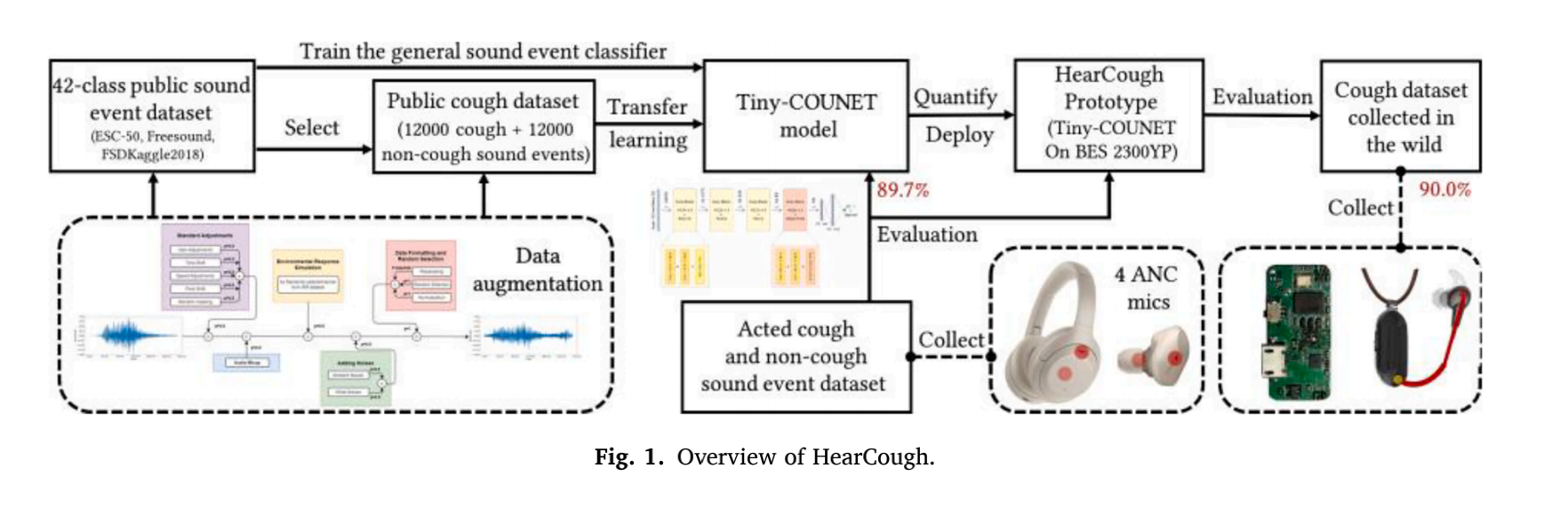
HearCough: Enabling continuous cough event detection on edge computing hearables
Abstract
Cough event detection is the foundation of any measurement associated with cough, one of the primary symptoms of pulmonary illnesses. This paper proposees HearCough, which enables continuous cough event detection on edge computing hearables, by leveraging always-on active noise cancellation (ANC)microphones in commodity hearables. Specifically, we proposed a lightweight end-to-end neural network model ——Tiny-COUNET and its transfer learning based traning method. When evaluated on our acted cough event dataset, Tiny-COUNET achieved equivalent detection performance but required significantly less computational resources and storage space than cutting-edge cough evernt detection methods. Then we implemented HearCough by quantifying and deploying the pre-trained Tiny-COUNNET to a popular micro-controller in consumer hearables. Lastly, we evaluated that HearCough is effective and reliable for continuous cough event detection through a field study with 8 patients. HearCough achieved 2 Hz cough event detection with an accuracy of 90.0% and an F1-score of 89.5% by consuming an additional 5.2mW power. We envision HearCough as a low-cost add-on for future hearables to enable continuous cough detection and pulmonary health monitoring.

GazeDock: Gaze-Only Menu Selection in Virtual Reality using Auto-Triggering Peripheral Menu
Abstract
Gaze-only input techniques in VR face the challenge of avoiding false triggering due to continuous eye tracking while maintaining interaction performance. In this paper, we proposed GazeDock, a technique for enabling fast and robust gaze-based menu selection in VR. GazeDock features a view-fixed peripheral menu layout that automatically triggers appearing and selection when the user's gaze approaches and leaves the menu zone, thus facilitating interaction speed and minimizing the false triggering rate. We built a dataset of 12 participants'natural gaze movements in typical VR applications. By analyzing their gaze movement patterns, we designed the menu UI personalization and optimized selection detection algorithm of GazeDock. We also examined users' gaze selection precision for targets on the peripheral menu and found that 4-8 menu items yield the highest throughput when considering both speed and accuracy. Finally, we validated the usability of GazeDock in a VR navigation game that contains both scene exploration and menu selection. Results showed that GazeDock achieved an average selection time of 471ms and a false triggering rate of 3.6%. And it received higher user preference ratings compared with dwell-based and pursuit-based techniques.
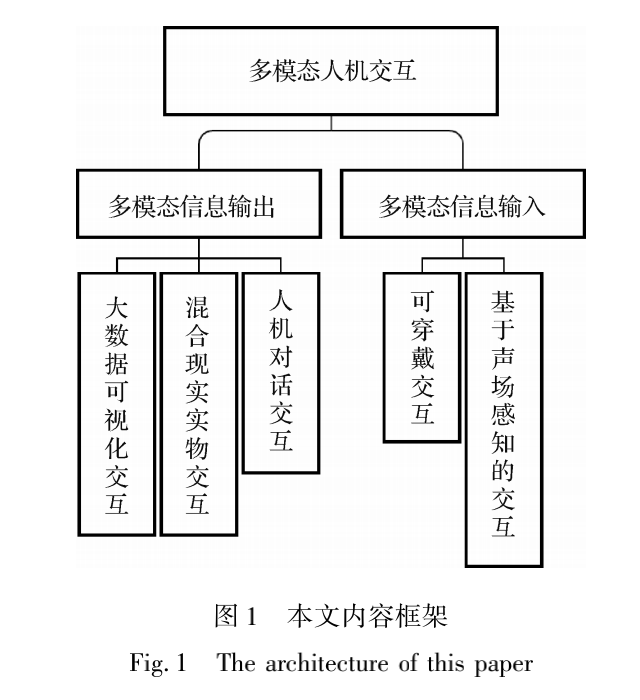
中国图象图形学报 | 多模态人机交互综述
Abstract
多模态人机交互旨在利用语音、图像、文本、眼动和触觉等多模态信息进行人与计算机之间的信息交换。在生理心理评估、办公教育、军事仿真和医疗康复等领域具有十分广阔的应用前景。本文系统地综述了多模态人机交互的发展现状和新兴方向,深入梳理了大数据可视化交互、基于声场感知的交互、混合现实实物交互、可穿戴交互和人机对话交互的研究进展以及国内外研究进展比较。本文认为拓展新的交互方式、设计高效的各模态交互组合、构建小型化交互设备、跨设备分布式交互、提升开放环境下交互算法的鲁棒性等是多模态人机交互的未来研究趋势。
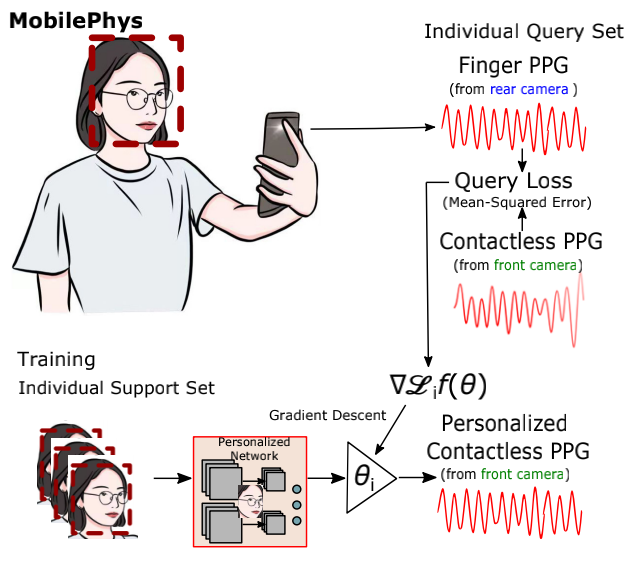
MobilePhys: Personalized Mobile Camera-Based Contactless Physiological Sensing
Abstract
Camera-based contactless photoplethysmography refers to a set of popular techniques for contactless physiological measurement. The current state-of-the-art neural models are typically trained in a supervised manner using videos accompanied by gold standard physiological measurements. However, they often generalize poorly out-of-domain examples (i.e., videos that are unlike those in the training set). Personalizing models can help improve model generalizability, but many personalization techniques still require some gold standard data. To help alleviate this dependency, in this paper, we present a novel mobile sensing system called MobilePhys, the first mobile personalized remote physiological sensing system, that leverages both front and rear cameras on a smartphone to generate high-quality self-supervised labels for training personalized contactless camera-based PPG models. To evaluate the robustness of MobilePhys, we conducted a user study with 39 participants who completed a set of tasks under different mobile devices, lighting conditions/intensities, motion tasks, and skin types. Our
results show that MobilePhys significantly outperforms the state-of-the-art on-device supervised training and few-shot adaptation methods. Through extensive user studies, we further examine how does MobilePhys perform in complex real-world settings. We envision that calibrated or personalized camera-based contactless PPG models generated from our proposed dual-camera mobile sensing system will open the door for numerous future applications such as smart mirrors, fitness and mobile health applications.
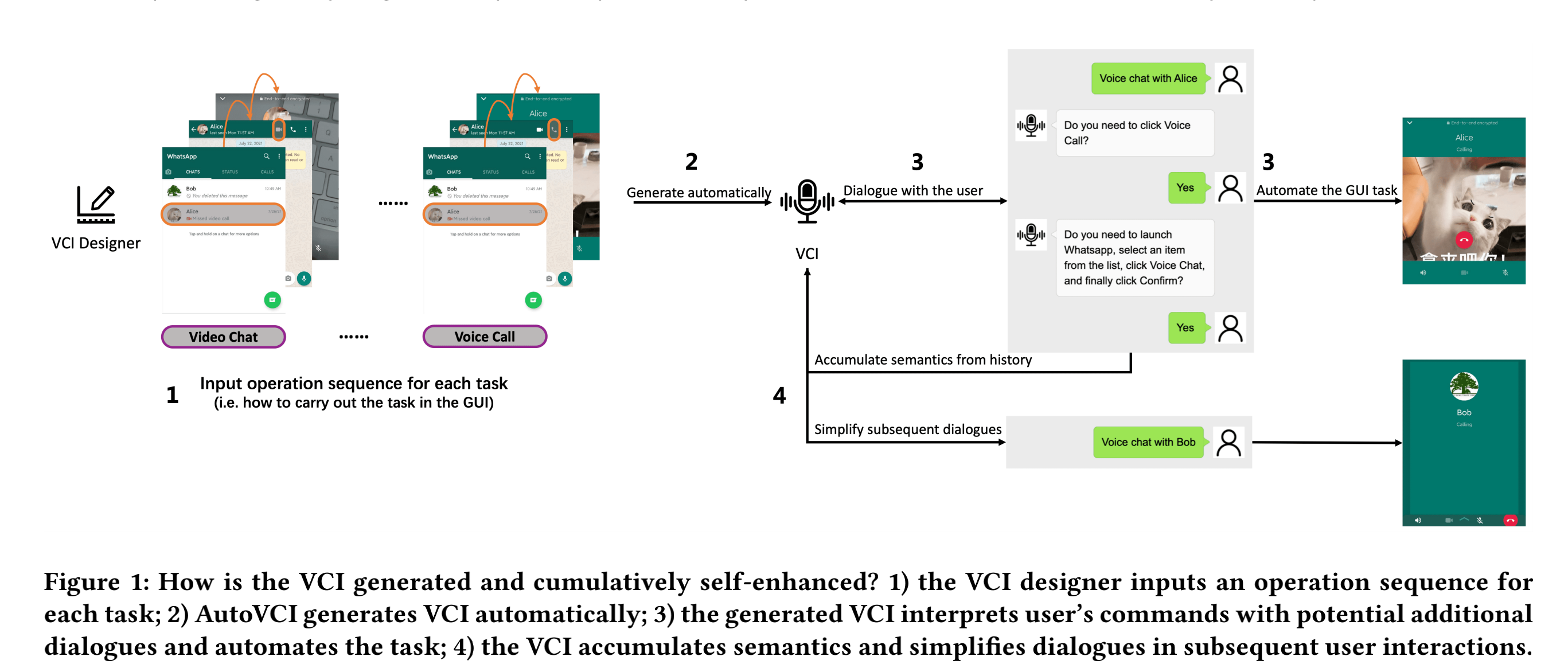
Automatically Generating and Improving Voice Command Interface from Operation Sequences on Smartphones
Abstract
Using voice commands to automate smartphone tasks (e.g., making a video call) can effectively augment the interactivity of numerous mobile apps. However, creating voice command interfaces requires a tremendous amount of effort in labeling and compiling the graphical user interface (GUI) and the utterance data. In this paper, we propose AutoVCI, a novel approach to automatically generate voice command interface (VCI) from smartphone operation sequences. The generated voice command interface has two distinct features. First, it automatically maps a voice command to GUI operations and fills in parameters accordingly, leveraging the GUI data instead of corpus or hand-written rules. Second, it launches a complementary Q&A dialogue to confirm the intention in case of ambiguity. In addition, the generated voice command interface can learn and evolve from user interactions. It accumulates the history command understanding results to annotate the user’s input and improve its semantic understanding ability. We implemented this approach on Android devices and conducted a two-phase user study with 16 and 67 participants in each phase. Experimental results of the study demonstrated the practical feasibility of AutoVCI.
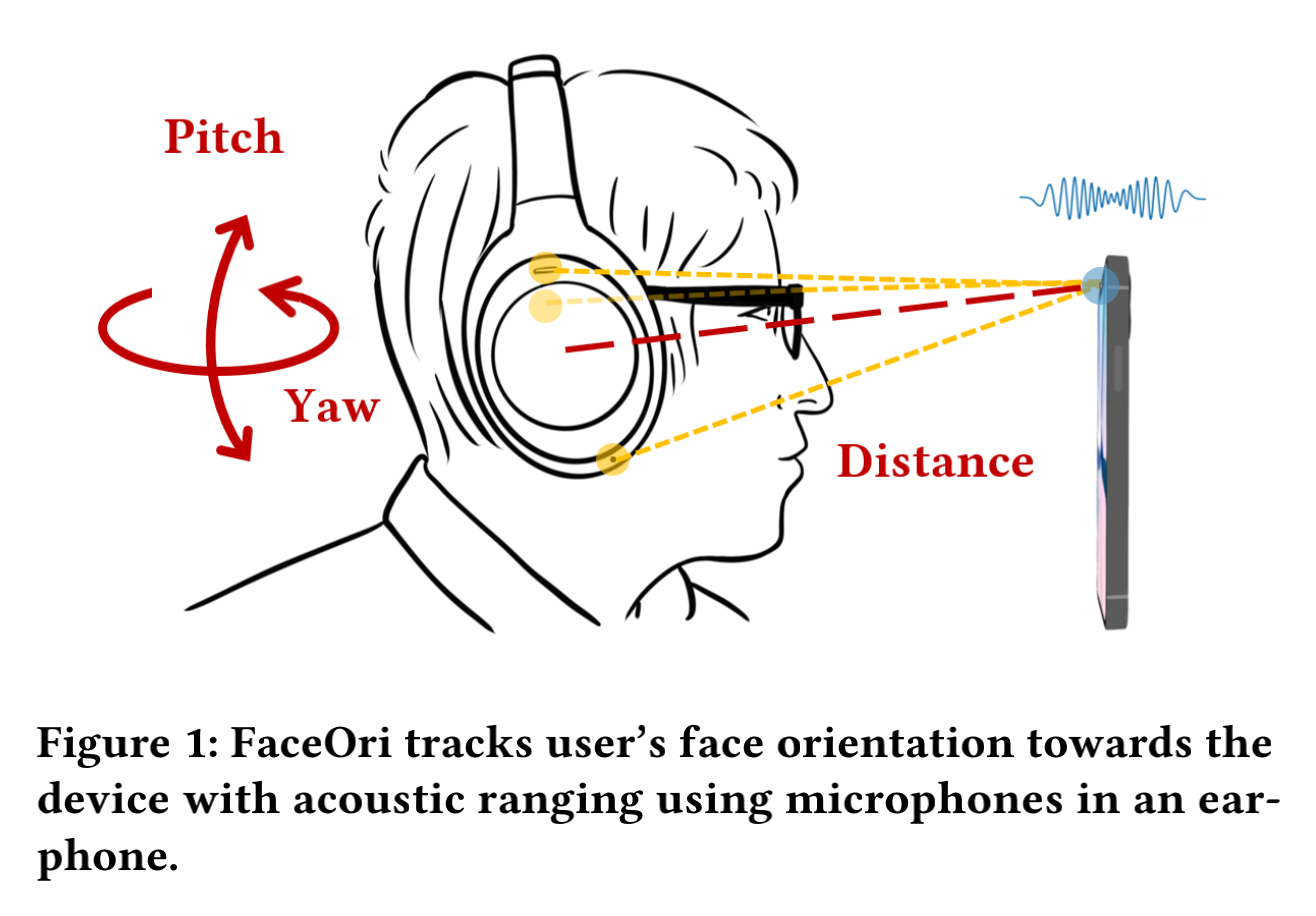
FaceOri: Tracking Head Position and Orientation Using Ultrasonic Ranging on Earphones
Abstract
Face orientation can often indicate users’ intended interaction target. In this paper, we propose FaceOri, a novel face tracking technique based on acoustic ranging using earphones. FaceOri can leverage the speaker on a commodity device to emit an ultrasonic chirp, which is picked up by the set of microphones on the user’s earphone, and then processed to calculate the distance from each microphone to the device. These measurements are used to derive the user’s face orientation and distance with respect to the device. We conduct a ground truth comparison and user study to evaluate FaceOri’s performance. The results show that the system can determine whether the user orients to the device at a 93.5% accuracy within a 1.5 meters range. Furthermore, FaceOri can continuously track user’s head orientation with a median absolute error of 10.9 mm in the distance, 3.7◦ in yaw, and 5.8◦ in pitch. FaceOri can allow for convenient hands-free control of devices and produce more intelligent context-aware interactions.