论文成果 / Publications
2025
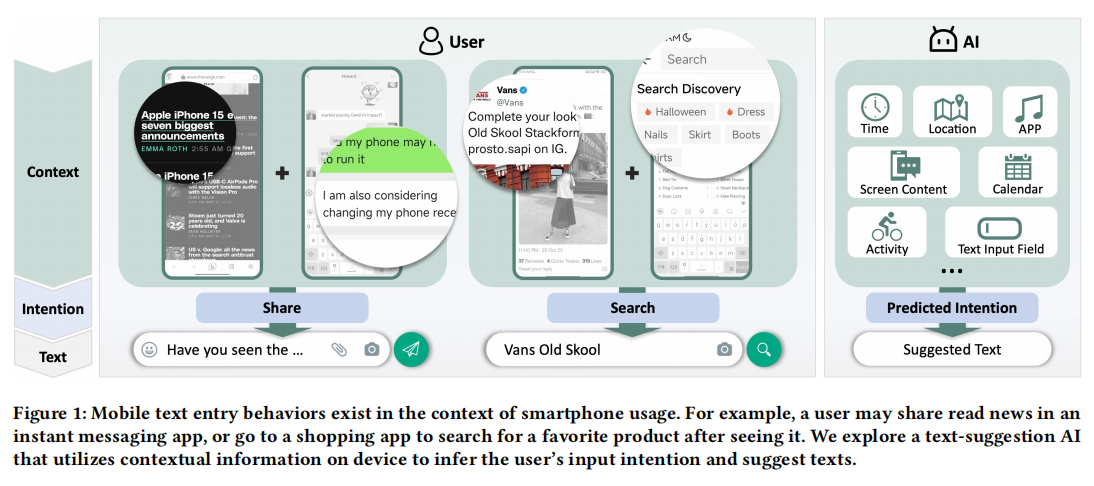
Investigating Context-Aware Collaborative Text Entry on Smartphones using Large Language Models
Abstract
Text entry is a fundamental and ubiquitous task, but users often face challenges such as situational impairments or difficulties in sentence formulation. Motivated by this, we explore the potential of large language models (LLMs) to assist with text entry in real-world contexts. We propose a collaborative smartphone-based text entry system, CATIA, that leverages LLMs to provide text suggestions based on contextual factors, including screen content, time, location, activity, and more. In a 7-day in-the-wild study with 36 participants, the system offered appropriate text suggestions in over 80% of cases. Users exhibited different collaborative behaviors depending on whether they were composing text for interpersonal
communication or information services. Additionally, the relevance of contextual factors beyond screen content varied across scenarios. We identified two distinct mental models: AI as a supportive facilitator or as a more equal collaborator. These findings outline the design space for human-AI collaborative text entry on smartphones.
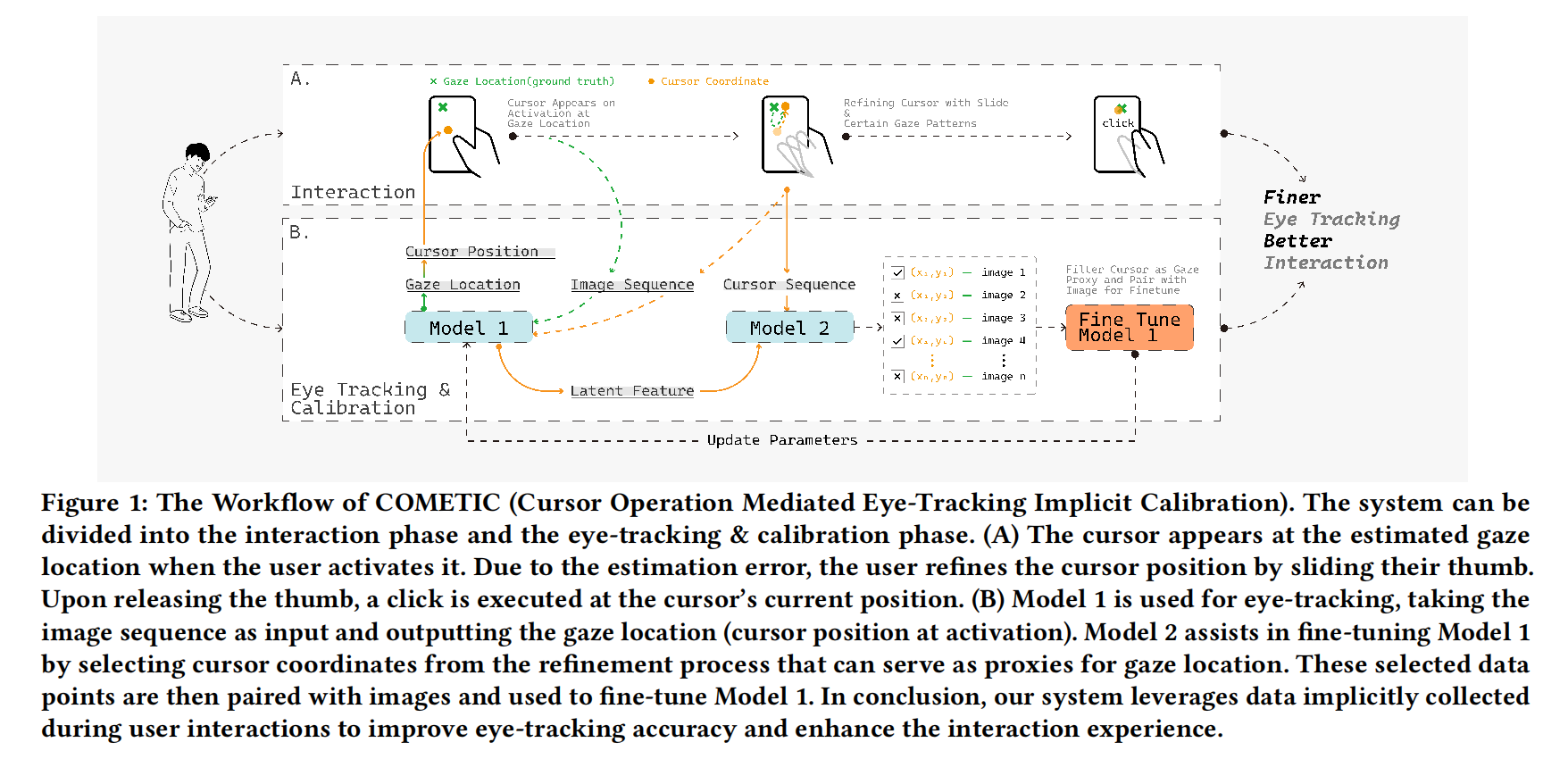
Enhancing Smartphone Eye Tracking with Cursor-Based Interactive Implicit Calibration
Abstract
The limited accuracy of eye-tracking on smartphones restricts its use. Existing RGB-camera-based eye-tracking relies on extensive datasets, which could be enhanced by continuous fine-tuning using
calibration data implicitly collected from the interaction. In this context, we propose COMETIC (Cursor Operation Mediated Eye-Tracking Implicit Calibration), which introduces a cursor-based interaction and utilizes the inherent correlation between cursor and eye movement. By filtering valid cursor coordinates as proxies for the ground truth of gaze and fine-tuning the eye-tracking model with corresponding images, COMETIC enhances accuracy during the interaction. Both filtering and fine-tuning use pre-trained models and could be facilitated using personalized, dynamically updated data. Results show COMETIC achieves an average eye-tracking error of 278.3 px (1.60 cm, 2.29◦), representing a 27.2% improvement compared to that without fine-tuning. We found that filtering cursor points whose actual distance to gaze is 150.0 px (0.86 cm) yields the best eye-tracking results.
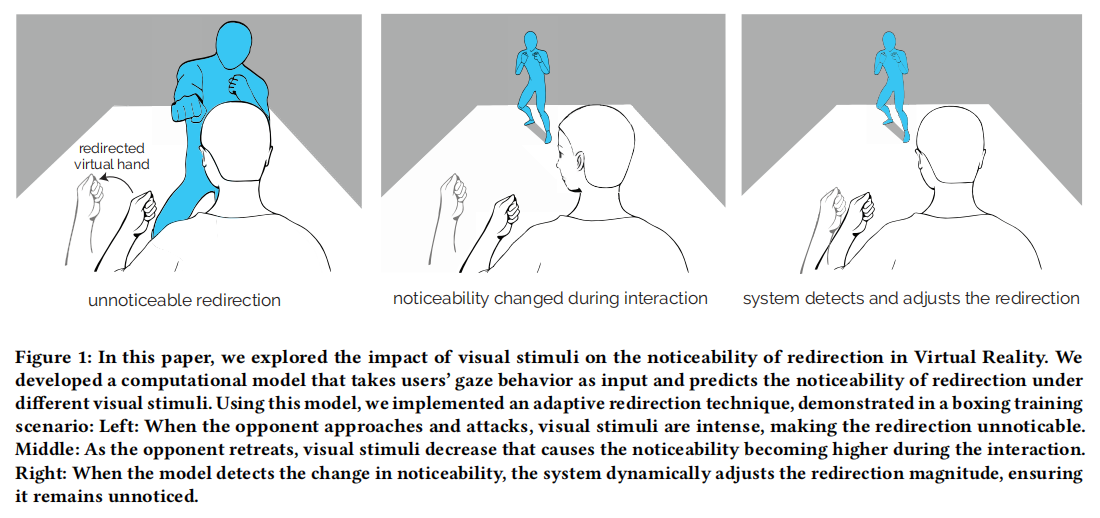
Modeling the Impact of Visual Stimuli on Redirection Noticeability with Gaze Behavior in Virtual Reality
Abstract
While users could embody virtual avatars that mirror theirphysical movements in Virtual Realty, these avatars'motions can be redirected to enable novel interactions. Excessive redirection,however,coud break the user's sense of embodiment due to pereptual con-flictsbetween vision and proprioception While prior work focused on avatar-related factors influencing the noticeability of redirection, we investigate how the visual stimuli in the surounading virtual environment affect user behavior and, in turn, the noticeability of redirection. Given the wide variety of ifferent types of vsual stimuli and their tendency to ehicit varying individual reactions, we propose to ue uers'gaze behavior as an indicator of the irrespanse to the stimuli and model thenoticeability of redirecfon.We conducted two user studies to collect users'gaze behavior and noticeability, invesigating the reationship between them and identifying the mast efective gaze behavior features for predicting noticeability.Based on the data,we developed a regre sion model that takes tusersgaze behavior as input and outputs the noticeability of redirection.We then conducted anevahuation study to test our model on u-seen visualstimuli,achieving an acuracyof 0.012 MSE.We further implemented am adaptive redirection technique and conducted apreliminary shudy to evaluate its effectiveness with complex visual stimalin two appications.The results indicated that participants experienced less physical demanding and a stronger sense of body ownership when using our adaptive technique,demonstrating the potential of our model to support real-world use cases.
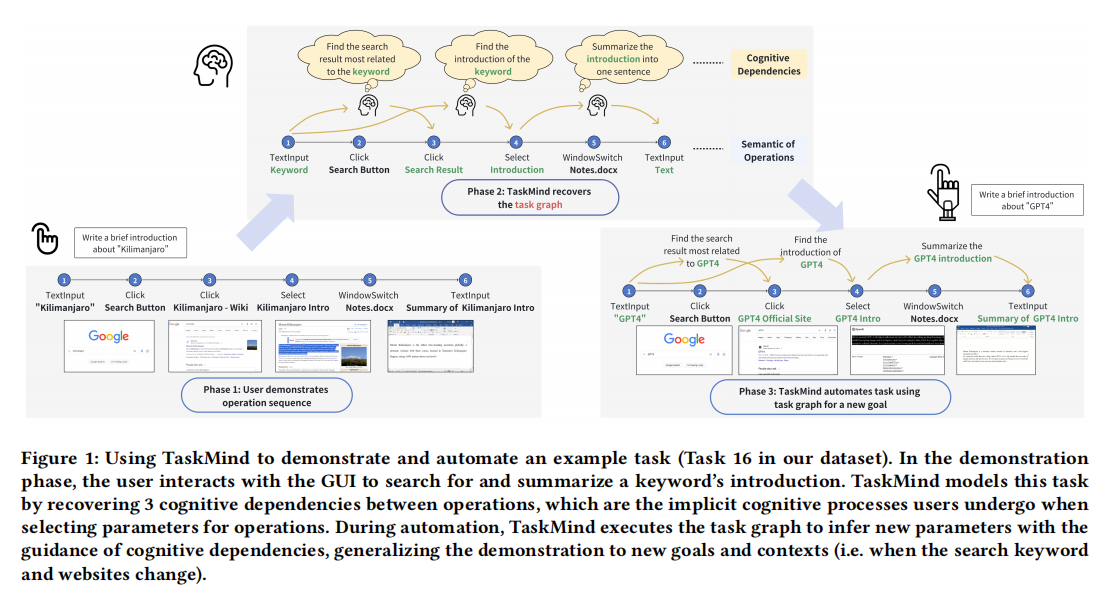
From Operation to Cognition: Automatic Modeling Cognitive Dependencies from User Demonstrations for GUI Task
Abstract
TraditioralProgrnmming by Demonstation(PBD)systems pri-marily automate tasks by recording and replaying operations onGraphical User Interfaces(GUIs),without flly considering thecognitive praceses behind operat ions.This limits their ablity togeneralize tasks with interdependent operations to new contexts(eg-cmlerting and smm arizing introductions depemding on diferentsaurch keywuorads frum wuried websies)We propose TaskMind,asystem that zanutomaticaly identifies the semantics of operations,andthe cognitive dependencies between cperations from demonstra-tions,building a user-interpretable taskgraph Users modify thisgraph to define new taskgoals,and TaskMind esecutes the graphto dynamically generalize new parameters for operations,withthe integration ofLarge Language Models(LLMs. We comparedTaskMind with a baseline end-to-end LLM which automates tasksfrom demonst raions and natral hanguage commands withouttask gaph In studies with 20 mrticipants on both predefined andcustomized tasks,TaskMind significantly outperforms the baselinein both succes rate and controlablity.
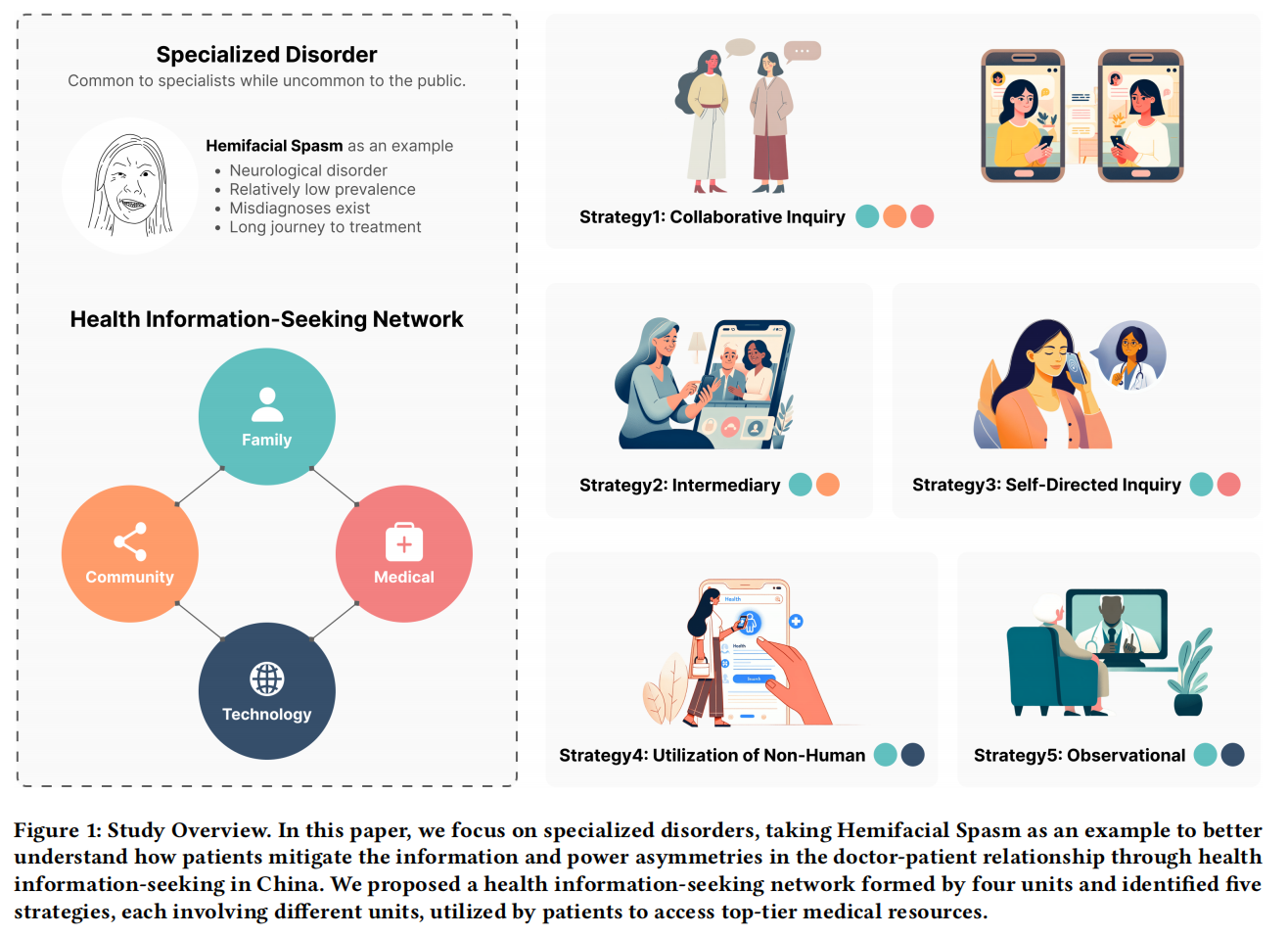
The Odyssey Journey: Top-Tier Medical Resource Seeking for Specialized Disorder in China
Abstract
It is pivotal for patients to receive accurate health information, diagnoses, and timely treatments. However, in China, the significant imbalanced doctor-to-patient ratio intensifes the information and power asymmetries in doctor-patient relationships. Health information-seeking, which enables patients to collect information
from sources beyond doctors, is a potential approach to mitigate these asymmetries. While HCI research predominantly focuses on common chronic conditions, our study focuses on specialized disorders, which are often familiar to specialists but not to general practitioners and the public. With Hemifacial Spasm (HFS) as an example, we aim to understand patients’ health information and top-tier1 medical resource seeking journeys in China. Through interviews with three neurosurgeons and 12 HFS patients from rural and urban areas, and applying Actor-Network Theory, we provide empirical insights into the roles, interactions, and workfows of various actors in the health information-seeking network. We also identifed fve strategies patients adopted to mitigate asymmetries and access top-tier medical resources, illustrating these strategies as subnetworks within the broader health information-seeking network and outlining their advantages and challenges.
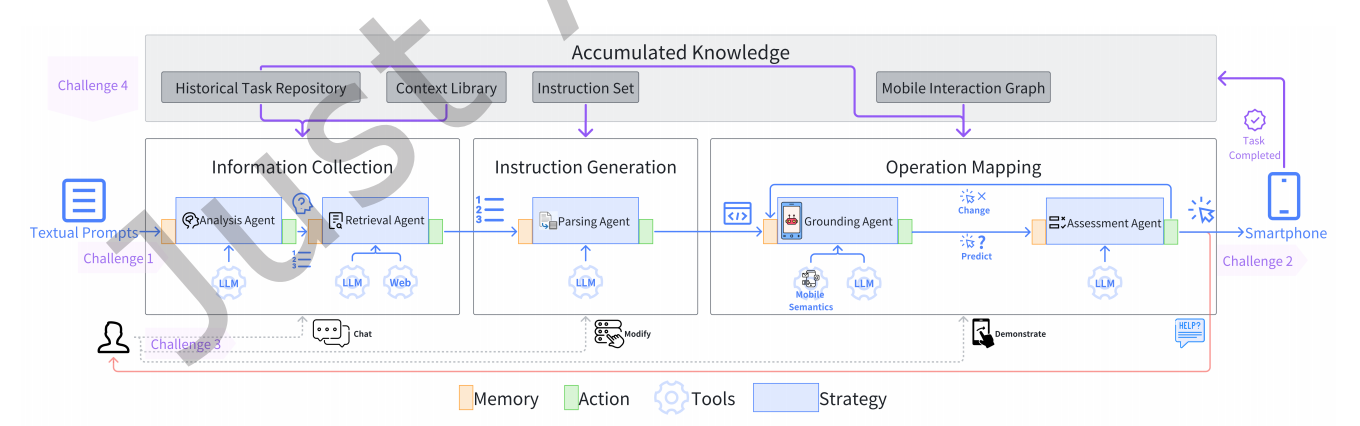
Prompt2Task: Automating UI Tasks on Smartphones from Textual Prompts
Abstract
UI task automation emables efficient task execution by simulating human interactions with graphical user interfaces(GUIs), without modifying the existing application code. However its broader adoption is constrained by the need for expertise in both scripting languages and workflow design. To address this challenge, we present Prompt2Task, a system designed to comprehend various task-related textual prompts (e.g., goals, procedures), thereby generating and performing the corresponding automation tasks. Prompt2Task incorporates a suite of intelligent agents that mimic human cognitive functions, specializing in interpreting
user intent, managing external information for task generation, and executing operations on smartphones. The agents can learn from user feedback and continuously improve their performance based on the accumulated knowledge. Experimental results indicated a performance jump from a 22.28% success rate in the baseline to 95.24% with Prompt2Task, requiring an average of 0.69 user interventions for each new task. Prompt2Task presents promising applications in fields such as tutorial creation, smart assistance, and customer service.
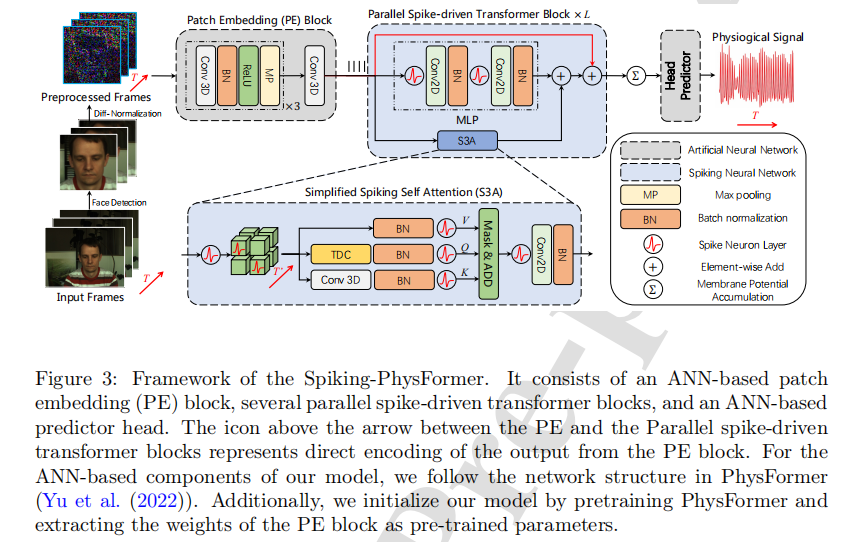
Spiking-PhysFormer: Camera-based remote photoplethysmography with parallel spike-driven transformer
Abstract
Artificial neural networks (ANNs) can help camera-based remote photoplethysmography (rPPG) in measuring cardiac activity and physiological signals from facial videos, such as pulse wave, heart rate and respiration rate with better accuracy. However, most existing ANN-based methods require substantial computing resources, which poses challenges for effective deployment on mobile devices. Spiking neural networks (SNNs), on the other hand, hold immense potential for energy-efficient deep learning owing to their binary and event-driven architecture. To the best of our knowledge, we are the first to introduce SNNs into the realm of rPPG, proposing a hybrid neural network (HNN) model, the Spiking-PhysFormer, aimed at reducing power consumption. Specifically, the proposed Spiking-PhyFormer consists of an ANN-based patch embedding block, SNN-based transformer blocks, and an ANN-based predictor head. First, to simplify the transformer block while preserving its capacity to aggregate local and global spatio-temporal features, we design a parallel spike transformer block to replace sequential sub-blocks. Additionally, we propose a simplified spiking self-attention mechanism that omits the value parameter without compromising the model’s performance. Experiments conducted on four datasets—PURE, UBFC-rPPG, UBFC-Phys, and MMPD demonstrate that the proposed model achieves a 10.1% reduction in power consumption compared to PhysFormer. Additionally, the power consumption of the transformer block is reduced by a factor of 12.2, while maintaining decent performance as PhysFormer and other ANN based models.

A Comparison Study Understanding the Impact of Mixed Reality Collaboration on Sense of Co-Presence
Abstract
Sense of co-presence refers to the perceived closeness and interaction between participants in a collaborative context, which critically impacts the collaboration experience and task performance. With the emergence of Mixed Reality (MR) technologies, we would like to investigate the effect of MR immersive collaboration environment on promoting co-presence in a remote setting by comparing it with non-MR methods, such as video conferencing. We conduct a comparison study, where we invited 14 dyads of participants to collaborate on block assembly tasks with video conferencing, MR system, and in a physically co-located scenario. Each participant of a dyad was assigned either a local worker to assemble the blocks or a remote helper to give the instructions. Results show that MR system can create comparable sense of co-presence with co-located situation, and allow users to interact more naturally with both the environment and each other. The adoption of mixed reality enhances collaboration and task performance by reducing reliance on verbal communication and favoring action-based interactions through gestures and direct manipulation of virtual objects.
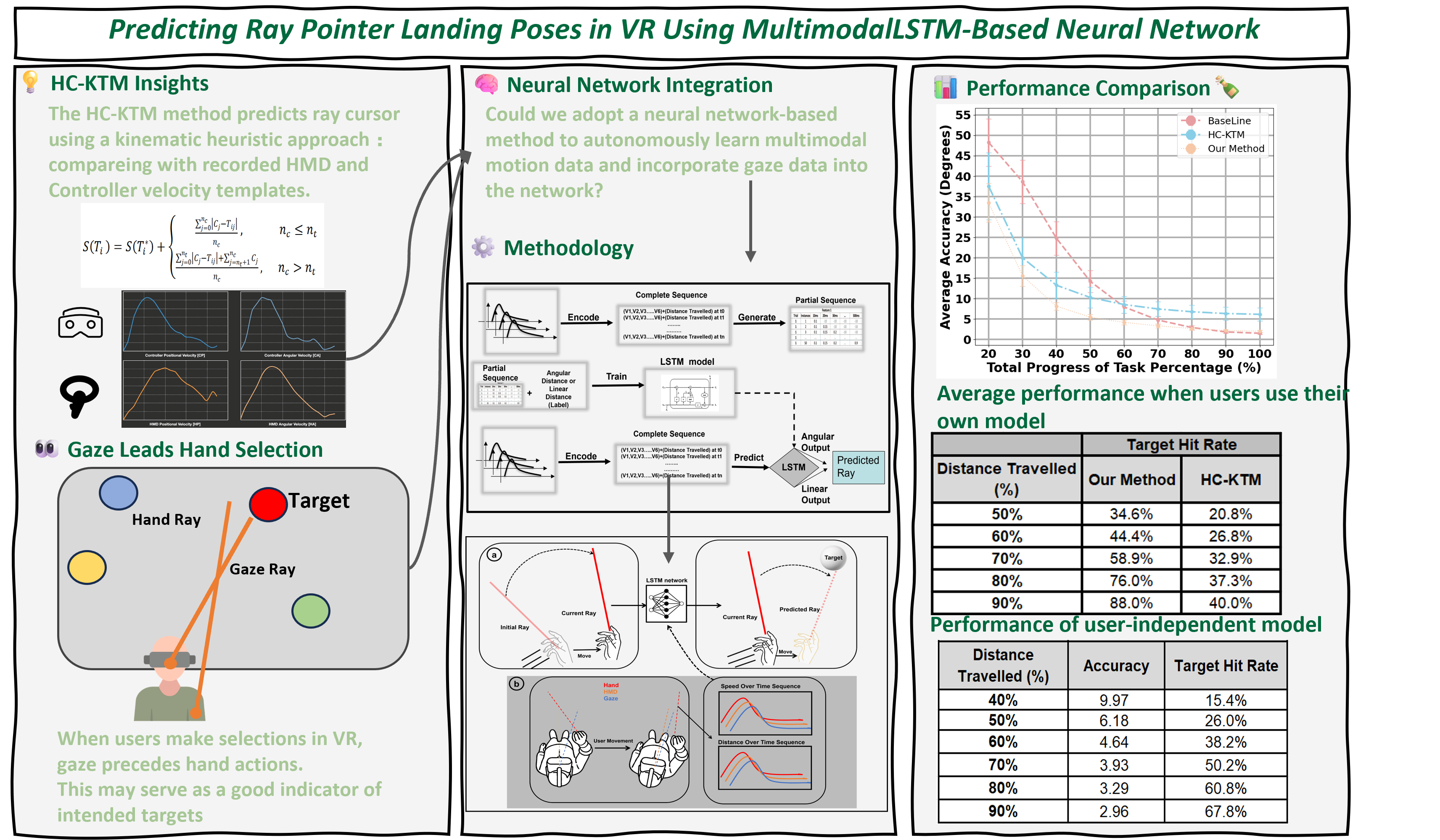
Predicting Ray Pointer Landing Poses in VR Using Multimodal LSTM-Based Neural Networks
Abstract
Taget selection is one of the most fundamenal tasks in VR interaction systems. Prediction heuristics can provide users with a smoother interastion eperience in this process. Our work aims to predict the ray landing pose for hand-baed raycasting selection in Virtual Reality (VR) using a Long Short-Tem Memory (LSTM)-based neural network with time-series data input of speed and distance over time from three different pose channels: hand,Head Moumted Display (HMD),and eye. We first conducted a sudy to collect motion data from these three input channels and analyzed these movement behaviors. Additionally, we evaluated which combination of input modalities yields the optimal result. A second study validates raycasting aross a continuous range of distances, angles, and target sizes. On average, our technique’s pedictions were within 4.6° of the true landing Pose when 50% of the way through the movement. We compared our LSTM neural network model to a kinematic infomation model and further validated its generalizability in two ways: by training the model on one user's data and testing on other users (cross-user) and by training on a group of users and testing on entirely new users (unseen users). Compared to the basline and a previous kinematic method, our model inereased prediction acuracy by a factor of 3.5 and 1.9, respectively, when 40% of the way through the movement.