论文成果 / Publications
2023
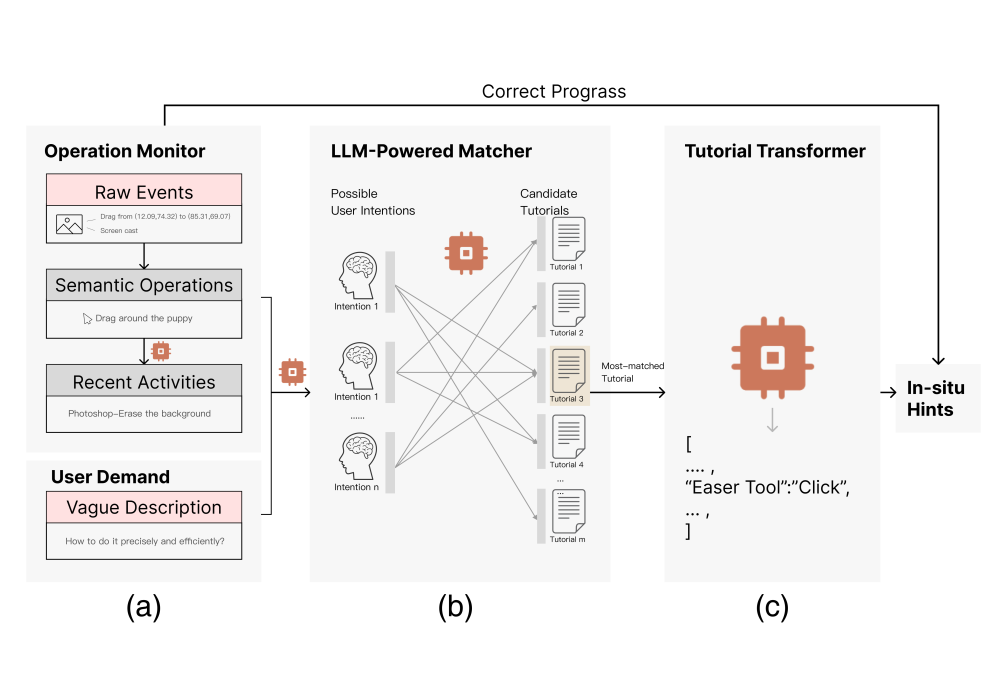
Docent: Digital Operation-Centric Elicitation of Novice-friendly Tutorials
Abstract
Nowadays, novice users often turn to digital tutorials for guidance in software. However, searching and utilizing the tutorial remains a challenge due to the request for proper problem articulation, extensive searches and mind-intensive follow-through. We introduce "Docent", a system designed to bridge this knowledge-seeking gap.Powered by Large Language Models (LLMs), Docent takes vague user input and recent digital operation contexts to reason, seek,
and present the most relevant tutorials in-situ. We assume that Docent smooths the user experience and facilitates learning of the software.

Lightron: A Wearable Sensor System that Provides Light Feedback to Improve Punching Accuracy for Boxing Novices
Abstract
This work presents ‘Lightron’, a wearable sensor system designed for boxing training assistance, improving punching accuracy for novices. This system combines accelerometers, stretch sensors, and flex sensors to detect the user’s movements, providing LED light feedback to the user. This adjustable design ensures a tight fit of the device to the body, allowing the sensor to collect accurate arm movement data without impeding training movements. A simple neural network is used to enable real-time motion detection and analysis, which can run on low-cost embedded devices. Contrary to merely using accelerometers on the wrist, Lightron collects motion data from the elbow and shoulder, enhancing the precision of punch accuracy assessment. Primary user studies conducted among boxing amateurs have shown that using Lightron in boxing training increases the performance of amateur players both in single and periodic training sessions, demonstrating its potential utility in the sports training domain.
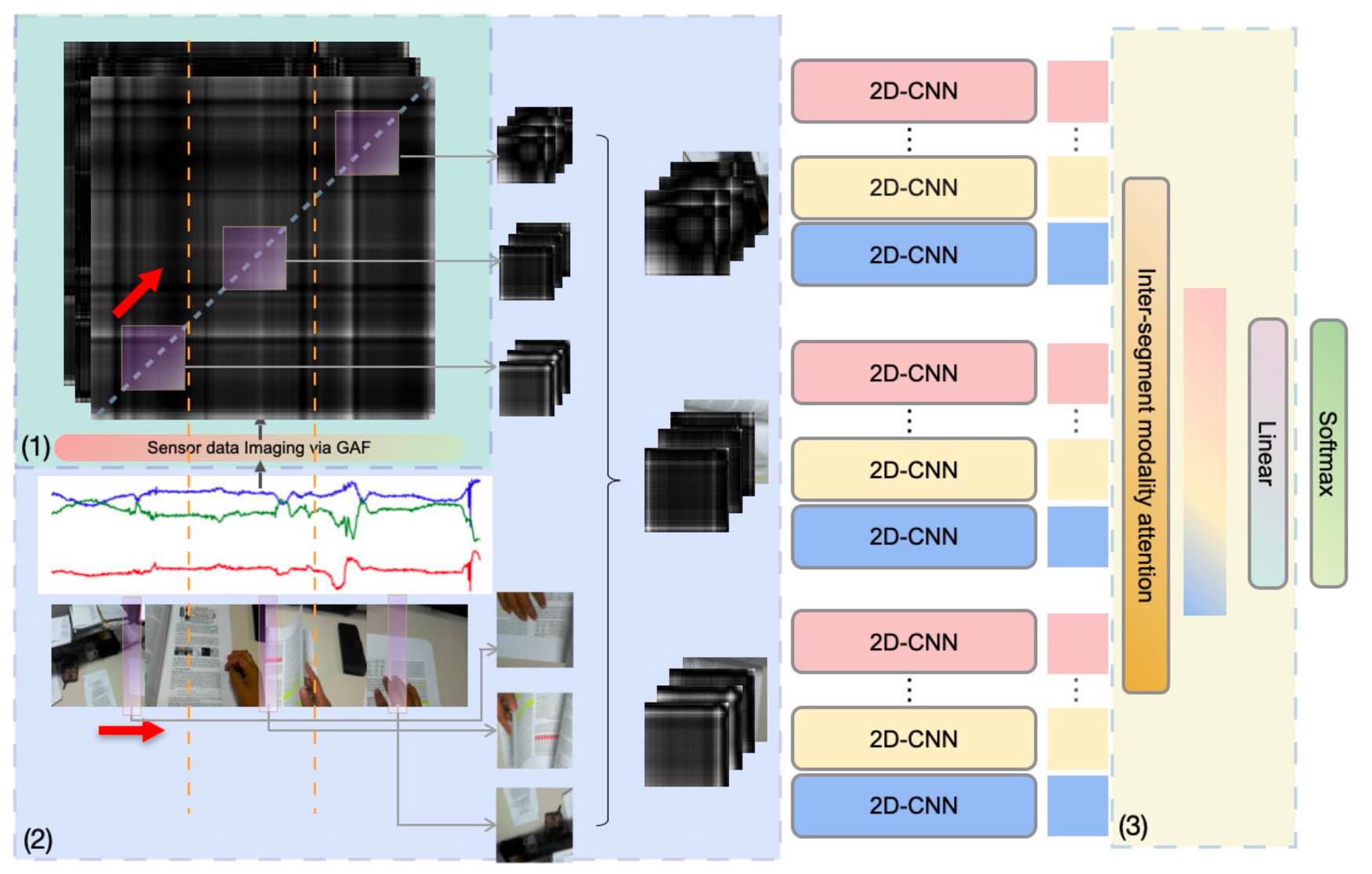
MMTSA: Multi-Modal Temporal Segment Attention Network for Efficient Human Activity Recognition
Abstract
Multimodal sensors provide complementary information to develop accurate machine-learning methods for human activity recognition (HAR), but introduce significantly higher computational load, which reduces efficiency. This paper proposes an efficient multimodal neural architecture for HAR using an RGB camera and inertial measurement units (IMUs) called Multimodal Temporal Segment Attention Network (MMTSA). MMTSA first transforms IMU sensor data into a temporal and structure-preserving gray-scale image using the Gramian Angular Field (GAF), representing the inherent properties of human activities. MMTSA then applies a multimodal sparse sampling method to reduce data redundancy. Lastly, MMTSA adopts an inter-segment attention module for efficient multimodal fusion. Using three well-established public datasets, we evaluated MMTSA's effectiveness and efficiency in HAR. Results show that our method achieves superior performance improvements (11.13% of cross-subject F1-score on the MMAct dataset) than the previous state-of-the-art (SOTA) methods. The ablation study and analysis suggest that MMTSA's effectiveness in fusing multimodal data for accurate HAR. The efficiency evaluation on an edge device showed that MMTSA achieved significantly better accuracy, lower computational load, and lower inference latency than SOTA methods.

ShadowTouch: Enabling Free-Form Touch-Based Hand-to-Surface Interaction with Wrist-Mounted Illuminant by Shadow Projection
Abstract
We present ShadowTouch, a novel sensing method to recognize the subtle hand-to-surface touch state for independent fingers based on optical auxiliary. ShadowTouch mounts a forward-facing light source on the user’s wrist to construct shadows on the surface in front of the fingers when the corresponding fingers are close to the surface. With such an optical design, the subtle vertical movements of near-surface fingers are magnified and turned to shadow features cast on the surface, which are recognizable for computer vision algorithms. To efficiently recognize the touch state of each finger, we devised a two-stage CNN-based algorithm that first extracted all the fingertip regions from each frame and then classified the touch state of each region from the cropped consecutive frames. Evaluations showed our touch state detection algorithm achieved a recognition accuracy of 99.1% and an F-1 score of 96.8% in the leave-one-out cross-user evaluation setting. We further outlined the hand-to-surface interaction space enabled by ShadowTouch’s sensing capability from the aspects of touch-based interaction, stroke-based interaction, and out-of-surface information and developed four application prototypes to showcase ShadowTouch’s interaction potential. The usability evaluation study showed the advantages of ShadowTouch over threshold-based techniques in aspects of lower mental demand, lower effort, lower frustration, more willing to use, easier to use, better integrity, and higher confidence.
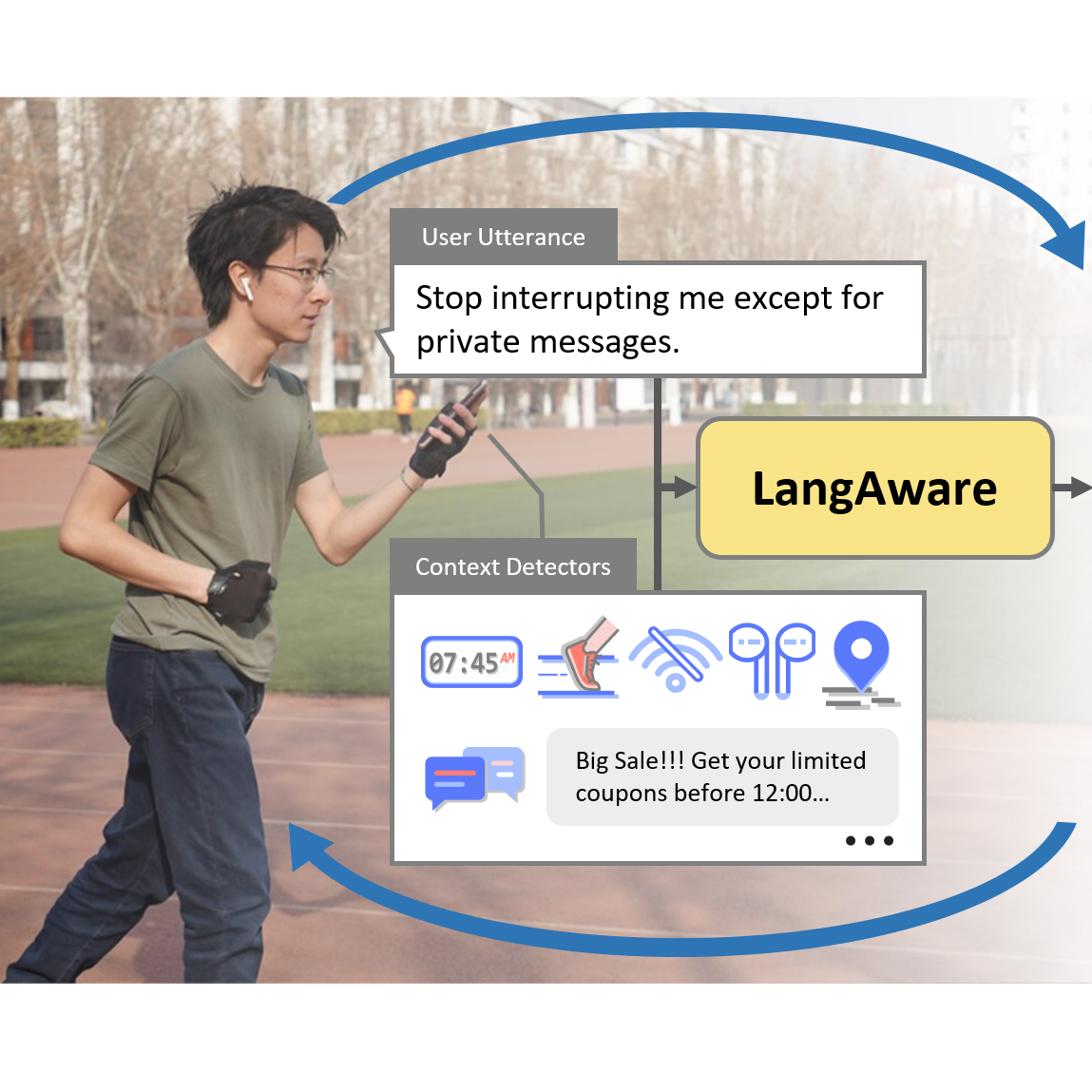
From Gap to Synergy: Enhancing Contextual Understanding through Human-Machine Collaboration in Personalized Systems
Abstract
This paper presents LangAware, a collaborative approach for constructing personalized context for context-aware applications. The need for personalization arises due to significant variations in context between individuals based on scenarios, devices, and preferences. However, there is often a notable gap between humans and machines in the understanding of how contexts are constructed, as observed in trigger-action programming studies such as IFTTT. LangAware enables end-users to participate in establishing contextual rules in-situ using natural language. The system leverages large language models (LLMs) to semantically connect low-level sensor detectors to high-level contexts and provide understandable natural language feedback for effective user involvement. We conducted a user study with 16 participants in real-life settings, which revealed an average success rate of 87.50% for defining contextual rules in a variety of 12 campus scenarios, typically accomplished within just two modifications. Furthermore, users reported a better understanding of the machine’s capabilities by interacting with LangAware.
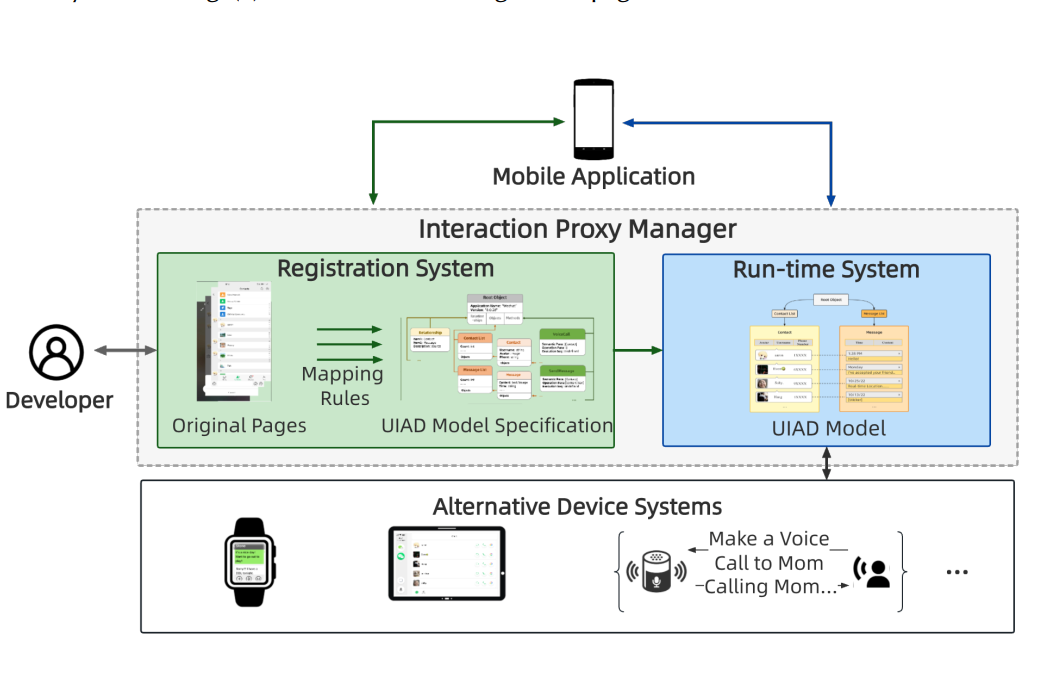
Interaction Proxy Manager: Semantic Model Generation and Run-time Support for Reconstructing Ubiquitous User Interfaces of Mobile Services
Abstract
Emerging terminals, such as smartwatches, true wireless earphones, in-vehicle computers, etc., are complementing our portals to ubiquitous information services. However, the current ecology of information services, encapsulated into millions of mobile apps, is largely restricted to smartphones; accommodating them to new devices requires tremendous and almost unbearable engineering efforts. Interaction Proxy, firstly proposed as an accessible technique, is a potential solution to mitigate this problem. Rather than re-building an entire application, Interaction Proxy constructs an alternative user interface that intercepts and translates interaction events and states between users and the original app’s interface. However, in such a system, one key challenge is how to robustly and efficiently “communicate” with the original interface given the instability and dynamicity of mobile apps (e.g., dynamic application status and unstable layout). To handle this, we first define UI-Independent Application Description (UIAD), a reverse-engineered semantic model of mobile services, and then propose Interaction Proxy Manager (IPManager), which is responsible for synchronizing and managing the original apps’ interface, and providing a concise programming interface that exposes information and method entries of the concerned mobile services. In this way, developers can build alternative interfaces without dealing with the complexity of communicating with the original app’s interfaces. In this paper, we elaborate the design and implementation of our IPManager, and demonstrate its effectiveness by developing three typical proxies, mobile-smartwatch, mobile-vehicle and mobile-voice. We conclude by discussing the value of our approach to promote ubiquitous computing, as well as its limitations.

MMPD: Multi-Domain Mobile Video Physiology Dataset
Abstract
Remote photoplethysmography (rPPG) is an attractive method for noninvasive, convenient and concomitant measurement of physiological vital signals. Public benchmark datasets have served a valuable role in the development of this technology and improvements in accuracy over recent years. However, there remain gaps in the public datasets. First, despite the ubiquity of cameras on mobile devices, there are few datasets recorded specifically with mobile phone cameras. Second, most datasets are relatively small and therefore are limited in diversity, both in appearance (e.g., skin tone), behaviors (e.g., motion) and environment (e.g., lighting conditions). In an effort to help the field advance, we present the Multidomain Mobile Video Physiology Dataset (MMPD), comprising 11 hours of recordings from mobile phones of 33 subjects. The dataset is designed to capture videos with greater representation
across skin tone, body motion, and lighting conditions. MMPD is comprehensive with eight descriptive labels and can be used in conjunction with the rPPG-toolbox. The reliability of the dataset is verified by mainstream unsupervised methods and neural methods. The GitHub repository of our dataset: https:
//github.com/THU-CS-PI/MMPD_rPPG_dataset.
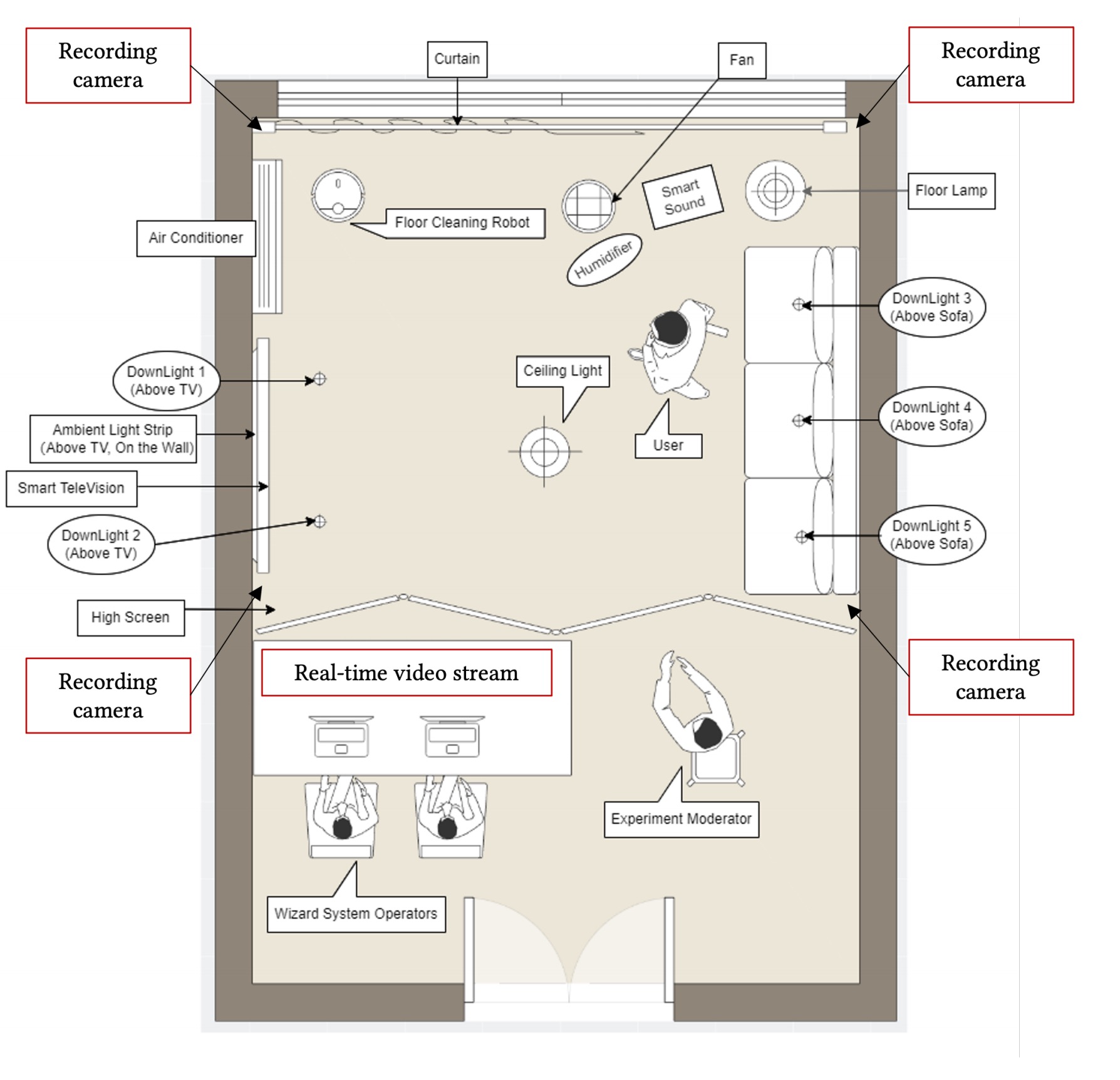
Understanding In-Situ Programming for Smart Home Automation
Abstract
Programming a smart home is an iterative process in which users configure and test the automation during the in-situ experience with IoT space. However, current end-user programming mechanisms are primarily preset configurations on GUI and fail to leverage in-situ behaviors and context. This paper proposed in-situ programming (ISP) as a novel programming paradigm for AIoT automation that extensively leverages users’ natural in-situ interaction with the smart environment. We built a Wizard-of-Oz system and conducted a user-enactment study to explore users’ behavior models in this paradigm. We identified a dynamic programming flow in which participants iteratively configure and confirm through query, control, edit, and test. We especially identified a novel method “snapshot” for automation configuration and a novel method “simulation”for automation testing, in which participants leverage ambient responses and in-situ interaction. Based on our findings, we proposed design spaces on dynamic programming flow, coherency and clarity of interface, and state and scene management to build an ideal in-situ programming experience.
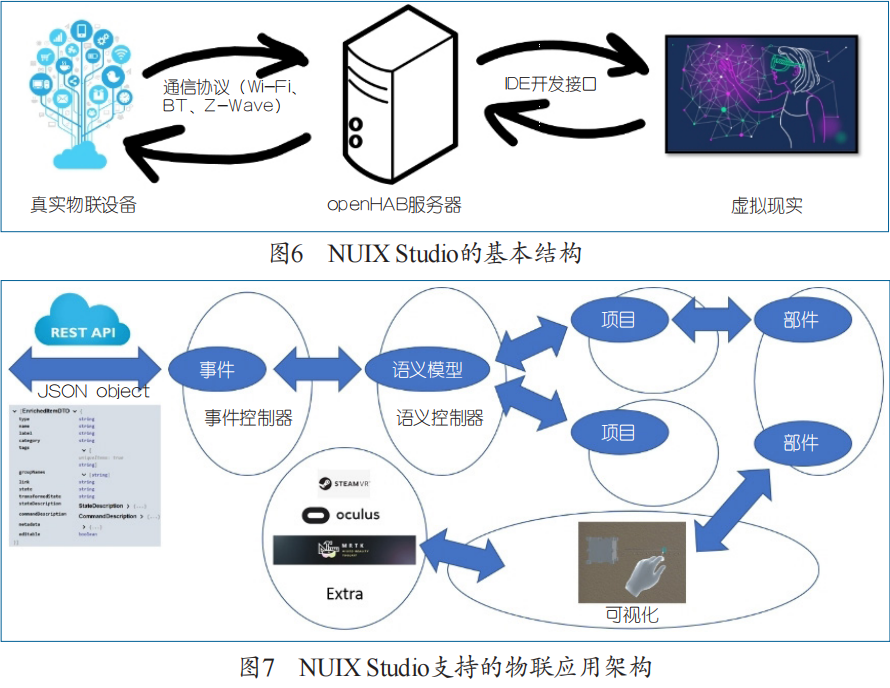
Communications of CCF | 从普适计算到人机境融合计算
Abstract
20 世纪 90 年代初,马克·维瑟(Mark Weiser)提出未来的普适 / 泛在计算(Ubiquitous Computing,同义术语还有 Pervasive Computing)将使计算脱离桌面,在掌上人机融合(移动)计算的基础上,建立起我们今天称之为人机境三元融合的交互环境 :更多的计算和感知能力将遁形于物理世界,构成持续服务于用户的分布式系统。近年来,信息技术不断朝此趋势发展,移动计算、云计算、物联网、大数据和人工智能等技术支撑越来越多不断成型的普适计算应用场景,如智慧城市、智能交通、工业物联网、智能家居等,人机境三元融合的计算平台将成为人类社会经济活动不可或缺的基础设施。普适计算场景是由人机境异构资源之间的数据融合关系构成的,其应用开发面临任务、资源、组合关系、编程需要专业领域知识等多方面的挑战,并且需要体现以人为中心的计算服务能力,而人又是三元中难以定义、只能适应的一方,更为复杂,这些复杂性需要靠操作系统来管理和屏蔽。