论文成果 / Publications
2023
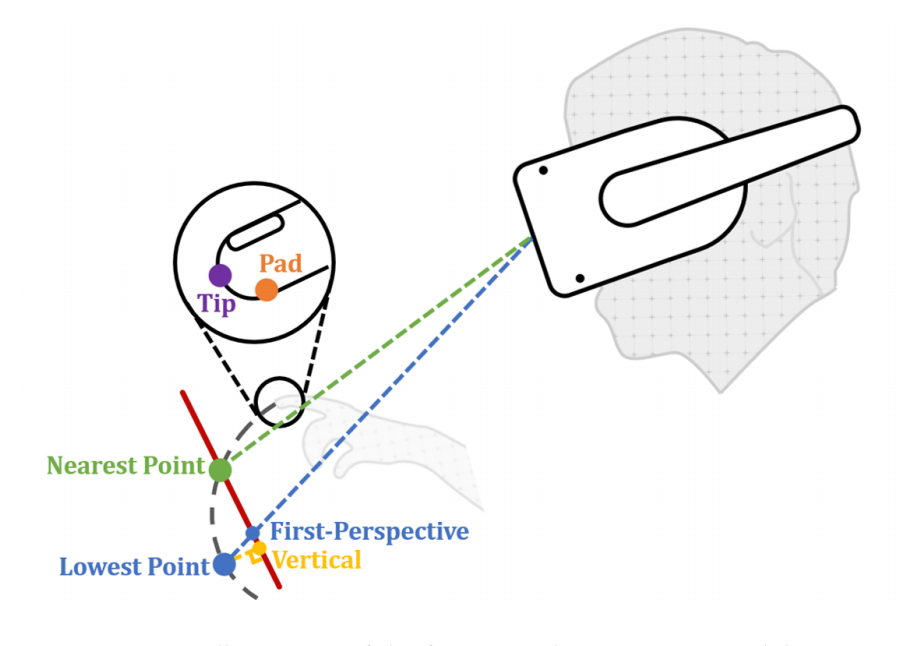
From 2D to 3D: Facilitating Single-Finger Mid-Air Typing on QWERTY Keyboards with Probabilistic Touch Modeling
Abstract
Mid-air text entry on virtual keyboards suffers from the lack of tactile feedback, which brings challenges to both tap detection and input prediction. In this paper, we explored the feasibility of single-finger typing on virtual QWERTY keyboards in mid-air. We first conducted a study to examine users’ 3D typing behavior on different sizes of virtual keyboards. Results showed that the participants perceived the vertical projection of the lowest point on the keyboard during a tap as the target location and inferring taps based on the intersection between the finger and the keyboard was not applicable. Aiming at this challenge, we derived a novel input prediction algorithm that took the uncertainty in tap detection into a calculation as probability, and performed probabilistic decoding that could tolerate false detection. We analyzed the performance of the algorithm through a full-factorial simulation. Results showed that the SVM-based probabilistic touch detection together with a 2D elastic probabilistic decoding algorithm (elasticity = 2) could achieve the optimal top-5 accuracy of 94.2%. In the evaluation user study, the participants reached a single-finger typing speed of 26.1 WPM with 3.2% uncorrected word-level
error rate, which was significantly better than both tap-based and gesture-based baseline techniques. Also, the proposed technique received the highest preference score from the users, proving its usability in real text entry tasks.
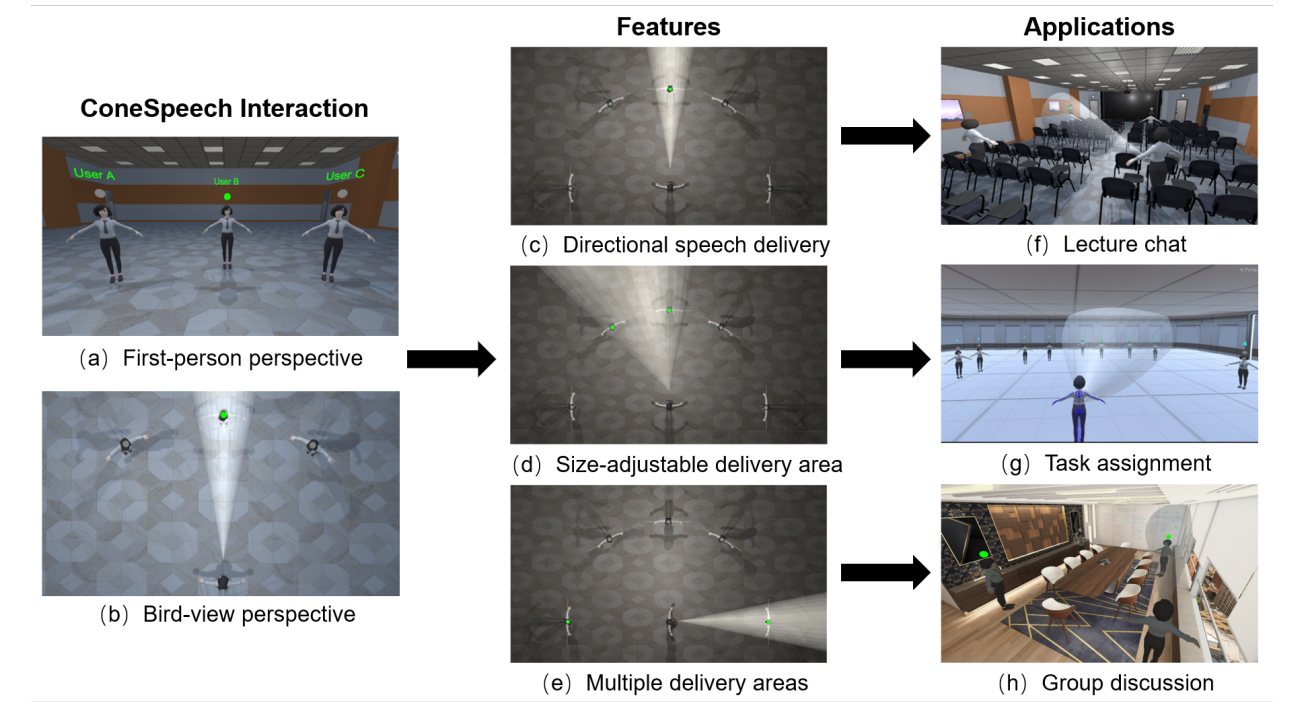
ConeSpeech: Exploring Directional Speech Interaction for Multi-Person Remote Communication in Virtual Reality
Abstract
Remote communication is essential for efficient collaboration among people at different locations. We present ConeSpeech, a virtual reality (VR) based multi-user remote communication technique, which enables users to selectively speak to target listeners without distracting bystanders. With ConeSpeech, the user looks at the target listener and only in a cone-shaped area in the direction can the listeners hear the speech. This manner alleviates the disturbance to and avoids overhearing from surrounding irrelevant people. Three featured functions are supported, directional speech delivery, size-adjustable delivery range, and multiple delivery areas, to facilitate speaking to more than one listener and to listeners spatially mixed up with bystanders. We conducted a user study to determine the modality to control the cone-shaped delivery area. Then we implemented the technique and evaluated its performance in three typical multi-user communication tasks by comparing it to two baseline methods. Results show that ConeSpeech balanced the convenience and flexibility of voice communication.
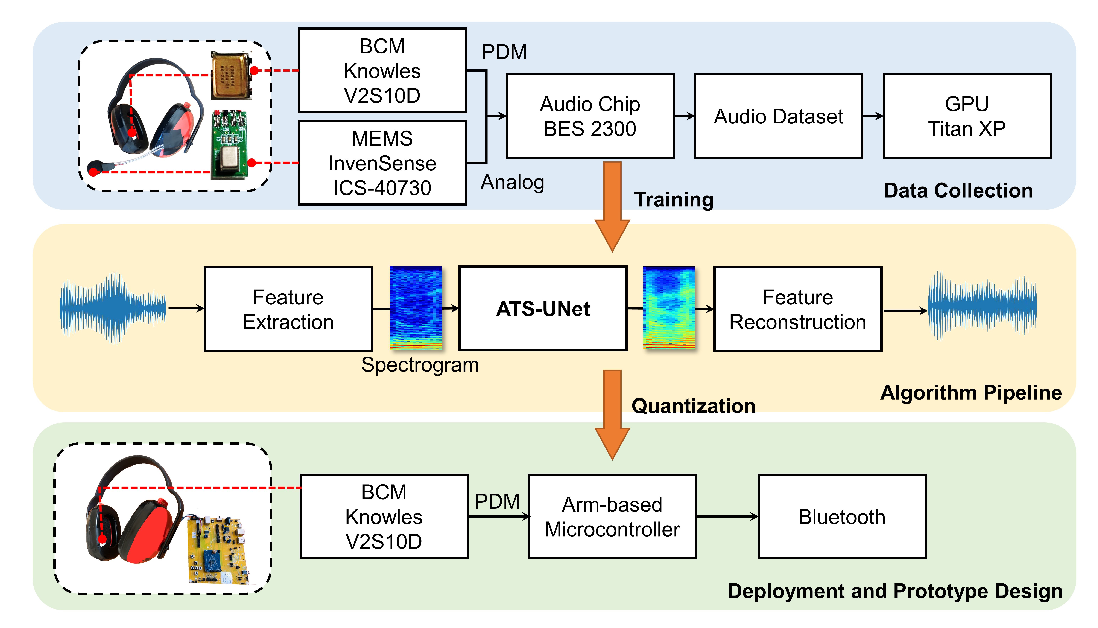
Enabling Real-Time On-Chip Audio Super Resolution for Bone-Conduction Microphones
Abstract
Voice communication using an air-conduction microphone in noisy environments suffers from the degradation of speech audibility. Bone-conduction microphones (BCM) are robust against ambient noises but suffer from limited effective bandwidth due to their sensing mechanism. Although existing audio super-resolution algorithms can recover the high-frequency loss to achieve high-fidelity audio,they require considerably more computational resources than is available in low-power hearable devices. This paper proposes the first-ever real-time on-chip speech audio super-resolution system for BCM.To accomplish this,we built and compared a series of lightweight audio super-resolution deep-learning models. Amongall these models,ATS-UNet was the most cost-efficient because the proposed novel Audio Temporal Shift Module (ATSM) reduces the network's dimensionality while maintaining sufficient temporal features from speech audio.Then,we quantized and deployed the ATS-UNet to low-end ARMmicro-controller units for a real-time embedded prototype. The evaluation results show that our system achieved real-time inference speed on Cortex-M7 and higher quality compared with thebaseline audio super-resolution method.Finally, we conducted a user study with ten experts andten amateur listeners to evaluate our method's effectiveness to human ears. Both groups perceived a significantly higher speech quality with our method when compared to the solutions with theoriginal BCM or air-conduction microphone with cutting-edge noise-reduction algorithms.
HandAvatar: Embodying Non-Humanoid Virtual Avatars through
Abstract
We propose HandAvatar to enable users to embody non-humanoid avatars using their hands. HandAvatar leverages the high dexterity and coordination of users’ hands to control virtual avatars, enabled through our novel approach for automatically-generated joint-to-joint mappings. We contribute an observation study to understand users’ preferences on hand-to-avatar mappings on eight avatars. Leveraging insights from the study, we present an automated approach that generates mappings between users’ hands and arbitrary virtual avatars by jointly optimizing control precision, structural similarity, and comfort. We evaluated HandAvatar on static posing, dynamic animation, and creative exploration tasks. Results indicate that HandAvatar enables more precise control, requires less physical effort, and brings comparable embodiment compared to a state-of-the-art body-to-avatar control method. We demonstrate HandAvatar’s potential with applications including non-humanoid avatar based social interaction in VR, 3D animation composition, and VR scene design with physical proxies. We believe thatHandAvatar unlocks new interaction opportunities, especially for usage in Virtual Reality, by letting users become the avatar in applications including virtual social interaction, animation, gaming, or education.
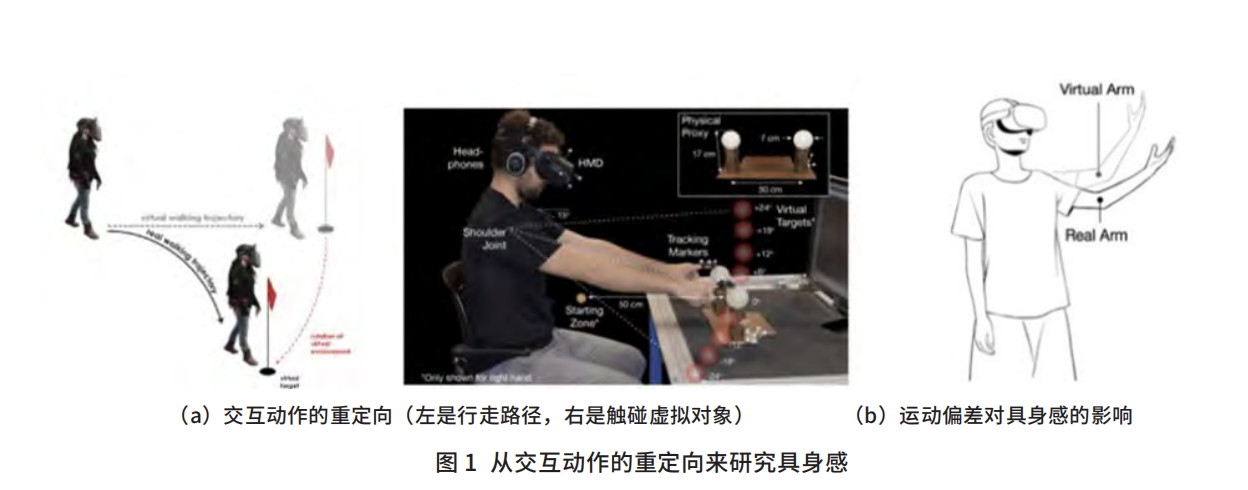
CAAI Communications|增强虚拟现实交互的具身感
Abstract
具身感(sense of embodiment)指人认为自己拥有、控制和处于一个身体的感觉,这个身体可能是自己,也可以是另外一个表示自己的虚拟对象。具身感起源于心理学中关于人的意识和身体关系的问题,随着虚拟现实的普及和元宇宙的兴起,使之成为一个需要研究的内容。
一个经典实验称之为“橡胶手错觉实验”,1998年发表在Nature的一篇论文中。实验很简单,一块挡板的两边有两只手,一只是被试者的真手,另外一只是橡胶手,实验员同时用毛刷刷两只手,当刷橡胶手,不刷真手时,被试者也会有被刷的感觉:甚至还做了比如拿东西去扎假橡胶手的实验时,真手也会有被扎的感觉,马上躲开。
这个心理学实验的一个有趣的结论是,虽然橡胶手是物理的假手不能动,也不逼真,但是用户对这只假橡胶手产生与他自身相关的感觉,现在称之为具身感的感觉。相比橡胶手,今天虚拟现实的交互中,提供用户的是一个可以同步其姿态、动作,甚至是表情等信息丰富的虚拟化身,因而自然而然产生一个问题,虚拟化身对用户具身感会产生什么影响?
2022
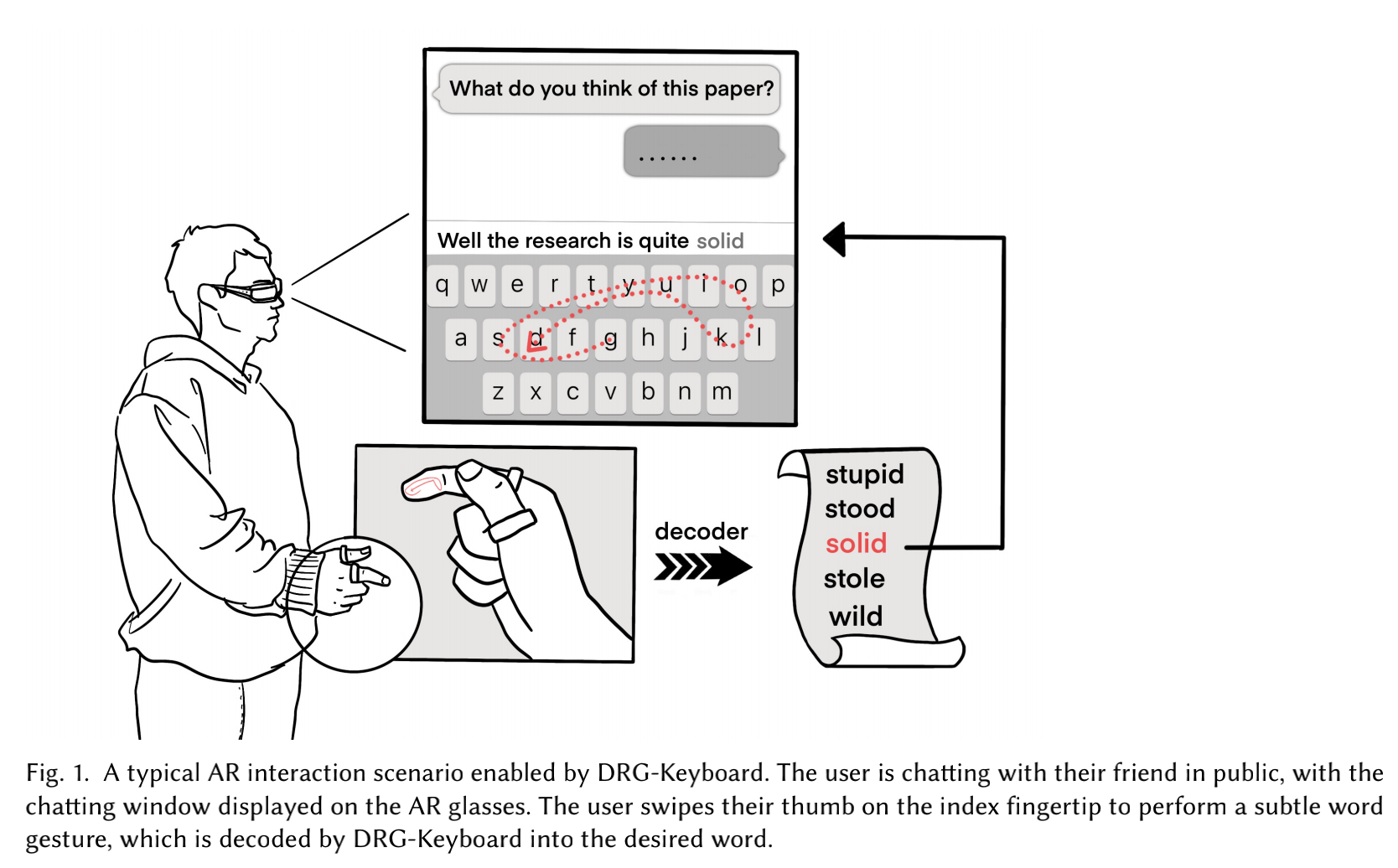
DRG-Keyboard: Enabling Subtle Gesture Typing on the Fingertip with Dual IMU Rings
Abstract
We present DRG-Keyboard, a gesture keyboard enabled by dualIMU rings,allowing the user to swipe the thumb on the index fingertip to perform word gesture typing as if typing on a miniature OWERTY keyboard. With dual IMUs attached to the user's thumb and index finger, DRG-Keyboard can 1)measure the relative attitude while mapping it to the 2D fingertip coordinates and 2) detect the thumb's touch-down and touch-up events combining the relative attitude data and the synchronous frequency domain data,based on which a fingertip gesture keyboard canbe implemented. To understand users typing behavior on the index fingertip with DRG-Keyboard,we collected and analyzed user data in two typing manners.Based on the statistics of the gesture data,we enhanced the elastic matching algorithm withrigid pruning and distance measurement transform.The user study showed DRG-Keyboard achieved an input speed of 12.9WPM(68.3%of their gesture typing speed on the smartphone for all participants. The appending study also demonstrated the superiority of DRG-Keyboard for better form factors and wider usage scenarios. To sum up, DRG-Keyboard not only achieves good text entry speed merely on a tiny fingertip input surface, but is also well accepted by the participants for the input subtleness, accuracy, good haptic feedback, and availability.
Investigating user-defined flipping gestures for dual-display phones
Abstract
Flipping is a potential interaction method for dual-display phones with front and rear screens. However, little is known about users’ phone flipping behaviors. To investigate it, we iteratively conduct three user studies in this research. We first elicit 36 flipping gestures from 22 users and present a design space according to the results. We then collect users’ flipping data and subjective evaluation of all user-defined gestures through the second user study. We design a flipping detection algorithm based on the data collected and deploy it on an off-the-shelf dual-display hone. Another evaluation study shows that it can detect users’ flipping efficiently with an average accuracy of 97.78%. Moreover, users prefer many flip-based applications on dual-display phones to existing non-flipping pproaches on regular single-screen phones. In conclusion, our work provides empirical support that flipping is an intuitive and promising input modality for dual-display phones and sheds light on its design implications.
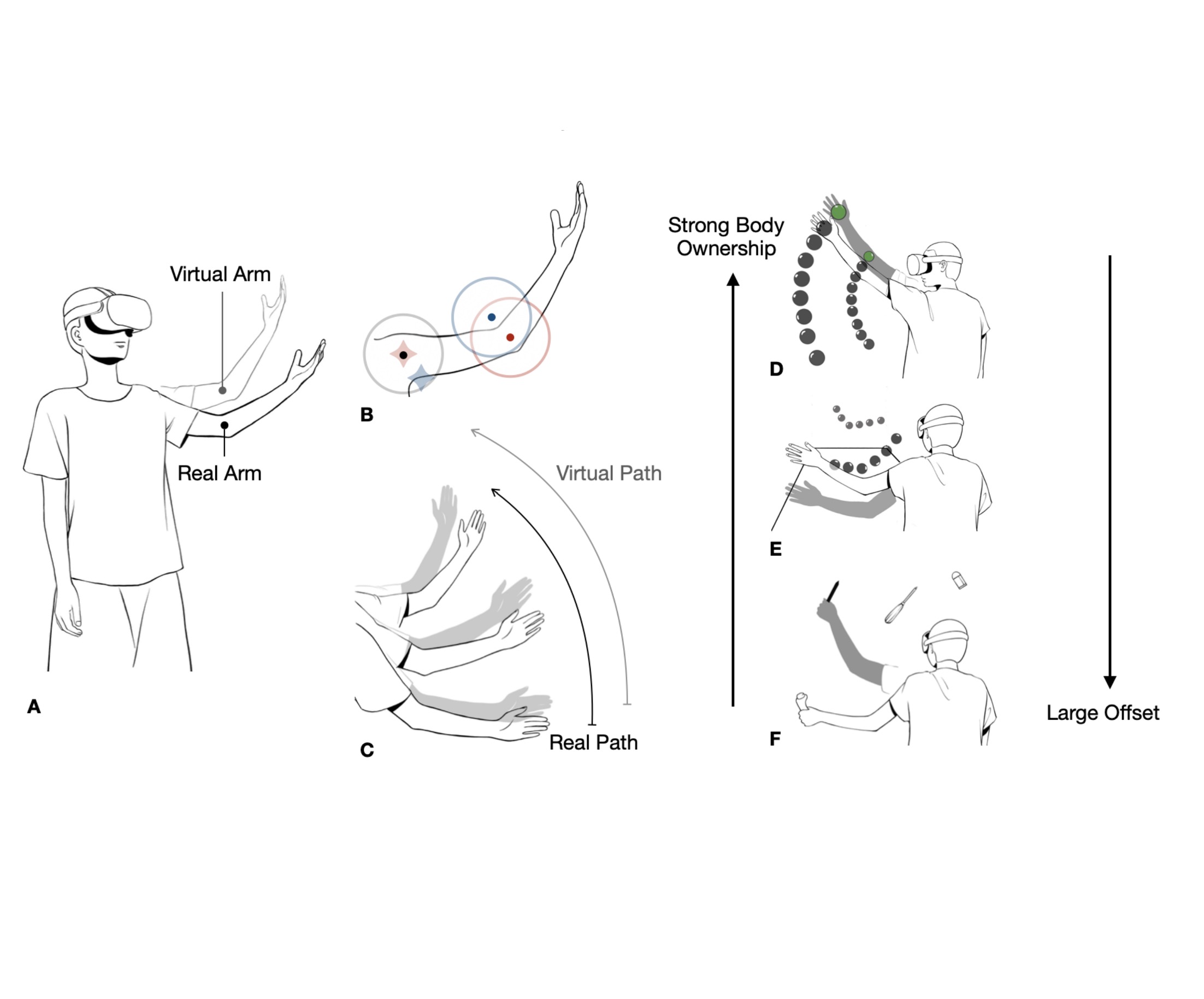
Modeling the Noticeability of User-Avatar Movement Inconsistency for Sense of Body Ownership Intervention
Abstract
An avatar mirroring the user’s movement is commonly adopted in Virtual Reality(VR). Maintaining the user-avatar movement consistency provides the user a sense of body ownership and thus an immersive experience. However, breaking this consistency can enable new interaction functionalities, such as pseudo haptic feedback or input augmentation, at the expense of immersion. We propose to quantify the probability of users noticing the movement inconsistency while the inconsistency amplitude is being enlarged, which aims to guide the intervention of the users’ sense of body ownership in VR. We applied angular offsets to the avatar’s shoulder and elbow joints and recorded whether the user identified the inconsistency through a series of three user studies and built a statistical model based on the results. Results show that the noticeability of movement inconsistency increases roughly quadratically with the enlargement of offsets and the offsets at two joints negatively affect the probability distributions of each other. Leveraging the model, we implemented a technique that amplifies the user’s arm movements with unnoticeable offsets and then evaluated implementations with different parameters(offset strength, offset distribution). Results show that the technique with medium-level and balanced-distributed offsets achieves the best overall performance. Finally, we demonstrated our model’s extendability in interventions in the sense of body ownership with three VR applications including stroke rehabilitation, action game and widget arrangement.
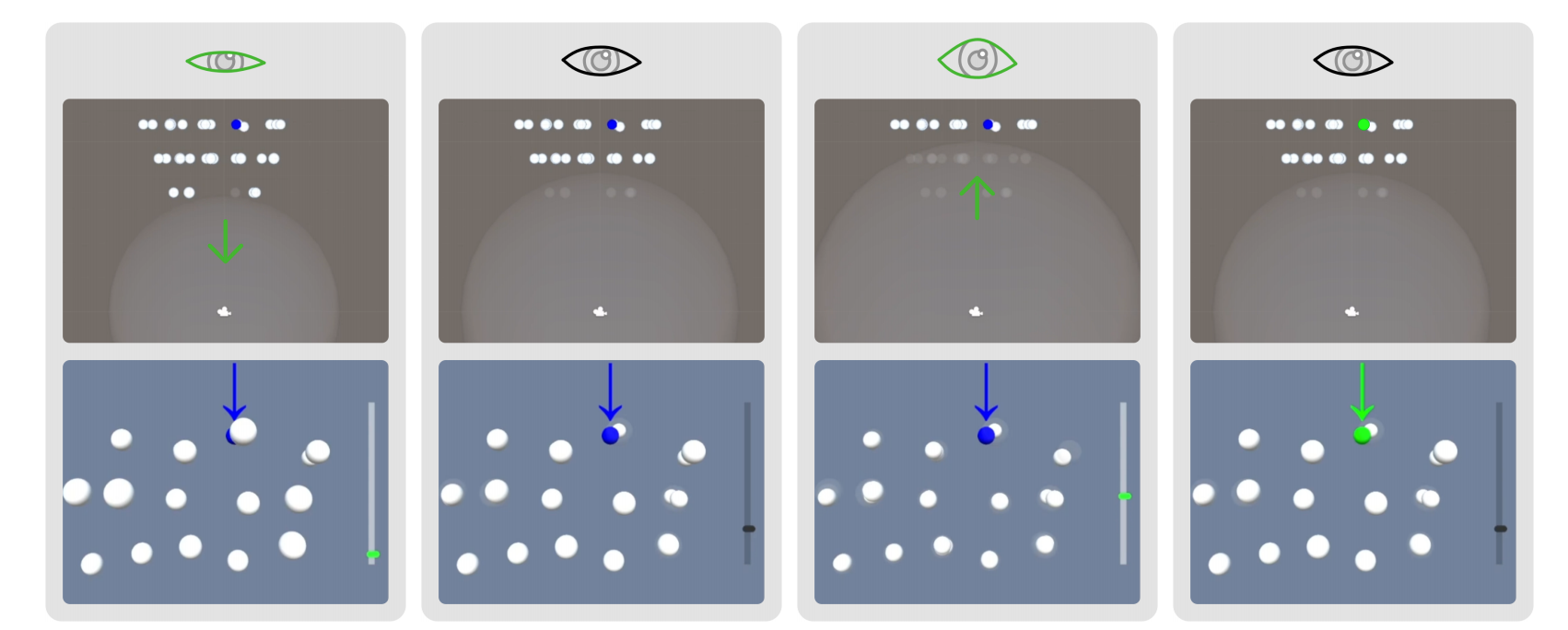
DEEP: 3D Gaze Pointing in Virtual Reality Leveraging Eyelid
Abstract
Gaze-based target sufers from low input precision and target occlusion. In this paper, we explored to leverage the continuous eyelid movement to support high-efcient and occlusion-robust dwellbased gaze pointing in virtual reality. We frst conducted two user studies to examine the users’ eyelid movement pattern both in unintentional and intentional conditions. The results proved the feasibility of leveraging intentional eyelid movement that was distinguishable with natural movements for input. We also tested the participants’ dwelling pattern for targets with diferent sizes and locations. Based on these results, we propose DEEP, a novel technique that enables the users to see through occlusions by controlling the aperture angle of their eyelids and dwell to select the targets with the help of a probabilistic input prediction model. Evaluation results showed that DEEP with dynamic depth and location selection incorporation signifcantly outperformed its static variants, as well as a naive dwelling baseline technique. Even for 100% occluded targets, it could achieve an average selection speed of 2.5s with an error rate of 2.3%.