论文成果 / Publications
2024
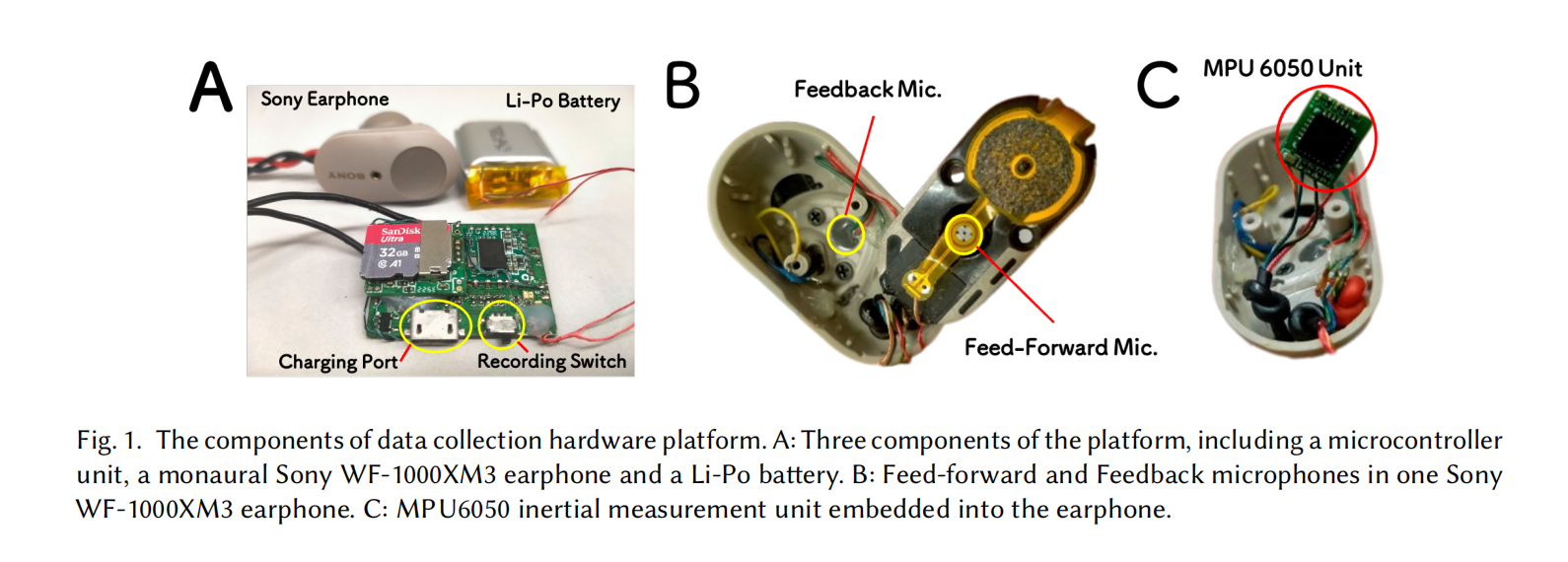
The EarSAVAS Dataset: Enabling Subject-Aware Vocal Activity Sensing on Earables
Abstract
Subject-aware vocal activity sensing on wearables,which specifically recognizes and monitors the wearer's distinct vocalactivities,is essential in advancing personal health monitoring and enabling context-aware applications.While recentadvancements in earables present new opportunities,the absence of relevant datasets and effective methods remains asignificant challenge.In this paper,we introduce EarSAVAS,the first publicly available dataset constructed specifically forsubject-aware human vocal activity sensing on earables.EarSAVAS encompasses eight distinct vocal activities from both theearphone wearer and bystanders,including synchronous two-channel audio and motion data collected from 42 participantstotaling 44.5 hours.Further,we propose EarVAS,a lightweight multi-modal deep learning architecture that enables efficientsubject-aware vocal activity recognition on earables.To validate the reliability of EarSAVAS and the efficiency of EarVAS, we implemented two advanced benchmark models.Evaluation results on EarSAVAS reveal EarVAS's effectiveness with anaccuracy of 90.84%and a Macro-AUC of 89.03%.Comprehensive ablation experiments were conducted on benchmark models and demonstrated the effectiveness of feedback microphone audio and highlighted the potential value of sensor fusion in subject-aware vocal activity sensing on earables. We hope that the proposed EarSAVAS and benchmark models can inspire other researchers to further explore efficient subject-aware human vocal activity sensing on earables.
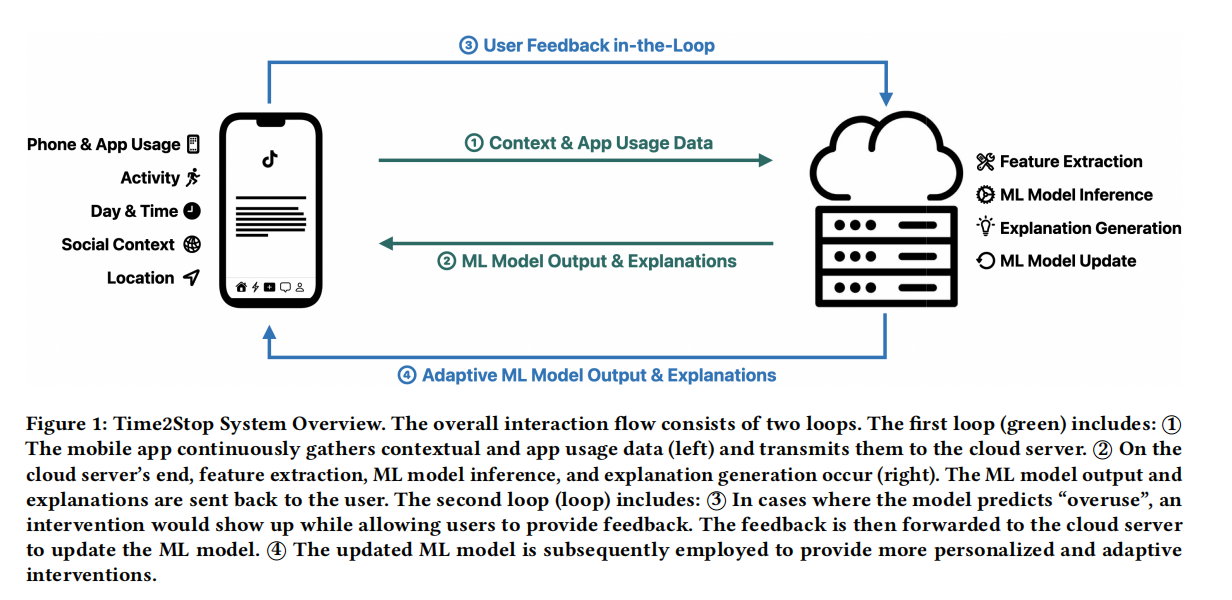
Time2Stop: Adaptive and Explainable Human-AI Loop for Smartphone Overuse Intervention
Abstract
Despite a rich history of investigating smartphone overuse intervention techniques, AI-based just-in-time adaptive intervention (JITAI) methods for overuse reduction are lacking. We develop Time2Stop, an intelligent, adaptive, and explainable JITAI system that leverages machine learning to identify optimal intervention timings, introduces interventions with transparent AI explanations, and collects user feedback to establish a human-AI loop and adapt the intervention model over time. We conducted an 8-week feld experiment (N=71) to evaluate the efectiveness of both the adaptation and explanation aspects of Time2Stop. Our results indicate that our adaptive models signifcantly outperform the baseline methods on intervention accuracy (>32.8% relatively) and receptivity(>8.0%). In addition, incorporating explanations further enhances the efectiveness by 53.8% and 11.4% on accuracy and receptivity, respectively. Moreover, Time2Stop signifcantly reduces overuse, decreasing app visit frequency by 7.0∼8.9%. Our subjective data also echoed these quantitative measures. Participants preferred the adaptive interventions and rated the system highly on intervention time accuracy, efectiveness, and level of trust. We envision our work can inspire future research on JITAI systems with a human-AI loop to evolve with users.
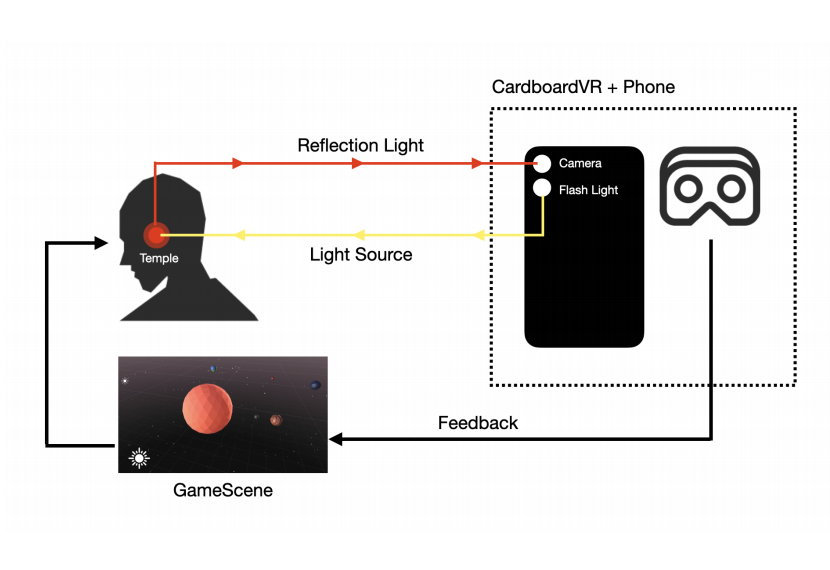
CardboardHRV: Bridging Virtual Reality and Biofeedback with a Cost-Effective Heart Rate Variability System
Abstract
We introduce CardboardHRV, an affordable and effective heart rate variability (HRV) biofeedback system leveraging Cardboard VR. Designed for easy access to HRV biofeedback without sacrificing therapeutic value, we adapted the Google Cardboard VR headset with an optical fiber modification. This enables the camera of the inserted phone to capture the photoplethysmography (PPG) signal from the user’s lateral forehead, enabling CardboardHRV to accurately calculate the heart rate variability as a basis for biofeedback. Furthermore, we’ve integrated an engaging biofeedback game to assist users throughout their sessions, enhancing user engagement and the overall experience. In a preliminary user evaluation, CardboardHRV demonstrated comparable therapeutic outcomes to traditional HRV biofeedback systems that require an additional electrocardiogram (ECG) device, proving itself as a more cost-effective and immersive alternative.
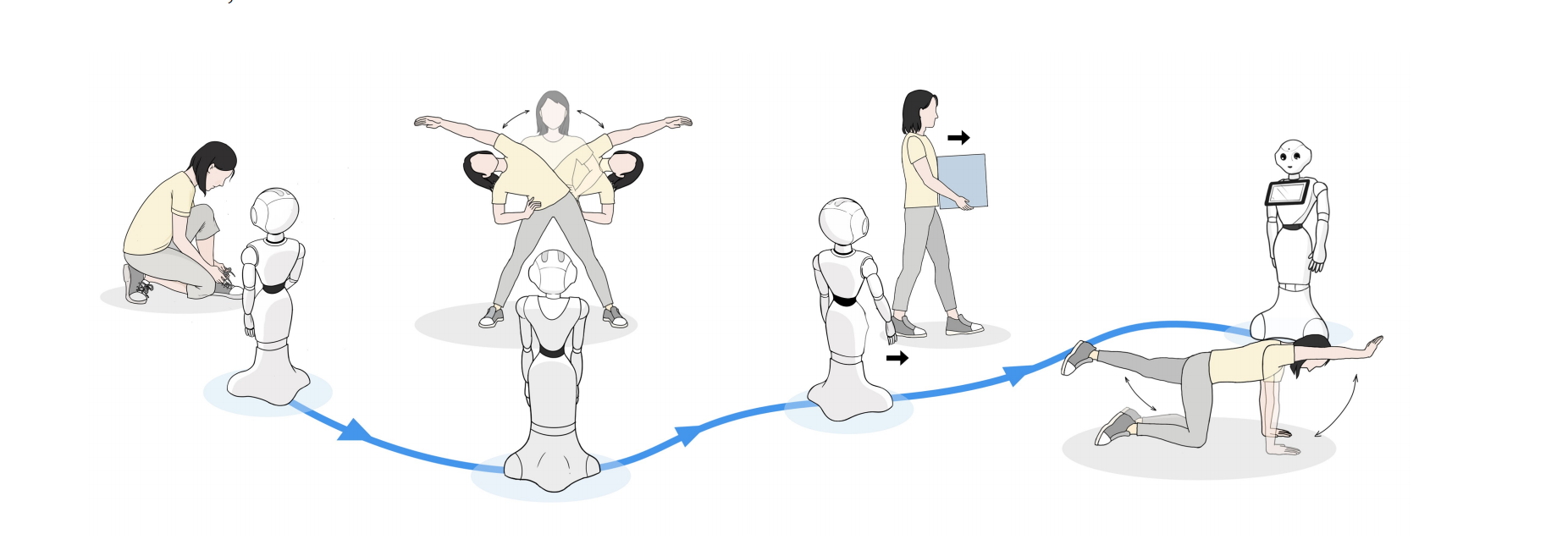
PepperPose: Full-Body Pose Estimation with a Companion Robot
Abstract
Accurate full-body pose estimation across diverse actions in a user friendly and location-agnostic manner paves the way for interactive applications in realms like sports, fitness, and healthcare. This task becomes challenging in real-world scenarios due to factors like the user’s dynamic positioning, the diversity of actions, and the varying acceptability of the pose-capturing system. In this context, we present PepperPose, a novel companion robot system tailored for optimized pose estimation. Unlike traditional methods, PepperPose actively tracks the user and refines its viewpoint, facilitating enhanced pose accuracy across different locations and actions. This allows users to enjoy a seamless action-sensing experience. Our evaluation, involving 30 participants undertaking daily functioning and exercise actions in a home-like space, underscores the robot’s promising capabilities. Moreover, we demonstrate the opportunities that PepperPose presents for human-robot interaction, its current limitations, and future developments.
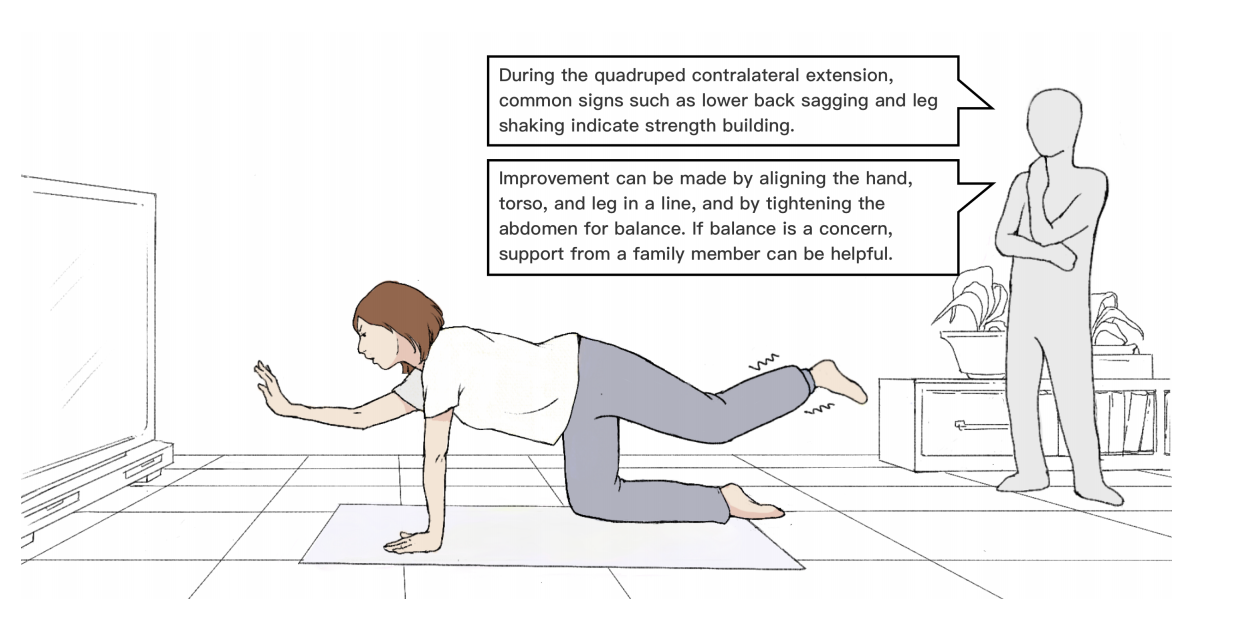
UbiPhysio: Support Daily Functioning, Fitness, and Rehabilitation with Action Understanding and Feedback in Natural Language
Abstract
We introduce UbiPhysio, a milestone framework that delivers fine-grained action description and feedback in natural language to support people’s daily functioning, fitness, and rehabilitation activities. This expert-like capability assists users in properly executing actions and maintaining engagement in remote fitness and rehabilitation programs. Specifically, the proposed UbiPhysio framework comprises a fine-grained action descriptor and a knowledge retrieval-enhanced feedback module. The action descriptor translates action data, represented by a set of biomechanical movement features we designed based on
clinical priors, into textual descriptions of action types and potential movement patterns. Building on physiotherapeutic domain knowledge, the feedback module provides clear and engaging expert feedback. We evaluated UbiPhysio’s performance through extensive experiments with data from 104 diverse participants, collected in a home-like setting during 25 types of everyday activities and exercises. We assessed the quality of the language output under different tuning strategies using standard benchmarks. We conducted a user study to gather insights from clinical physiotherapists and potential users about
our framework. Our initial tests show promise for deploying UbiPhysio in real-life settings without specialized devices.
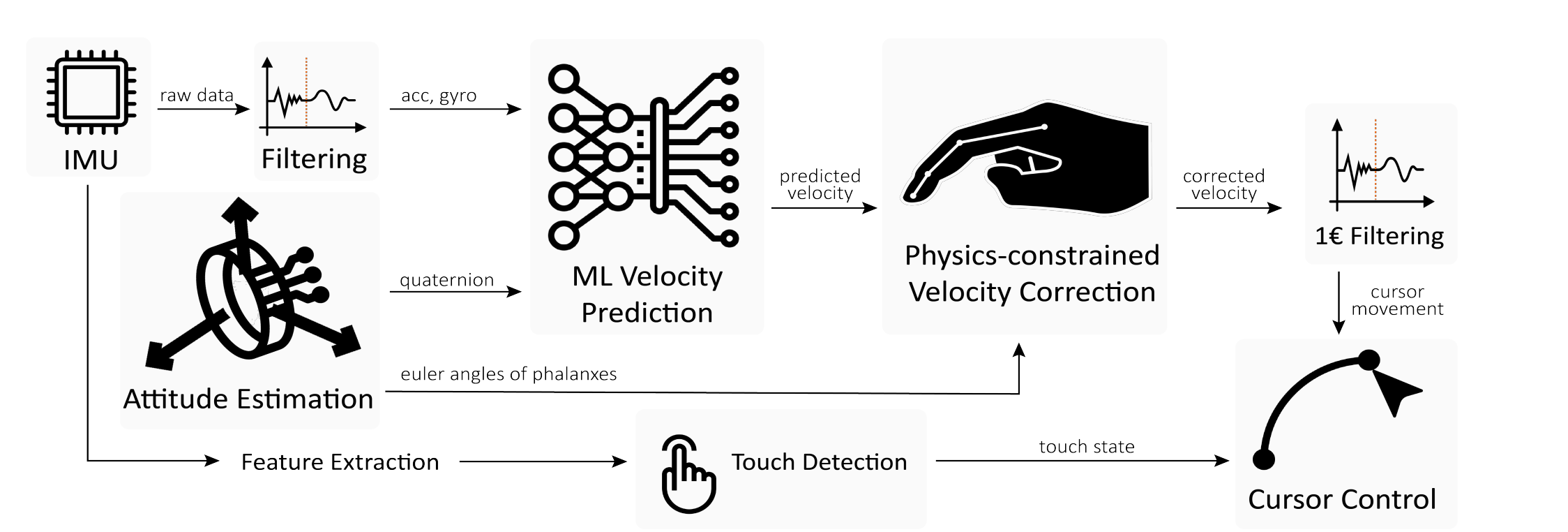
MouseRing: Always-available Touchpad Interaction with IMU Rings
Abstract
Tracking fine-grained finger movements with IMUs for continuous 2D-cursor control poses significant challenges due to limited sensing capabilities. Our findings suggest that finger-motion patterns and the inherent structure of joints provide beneficial physical knowledge, which lead us to enhance motion perception accuracy by integrating physical priors into ML models. We propose MouseRing, a novel ring-shaped IMU device that enables continuous finger-sliding on unmodified physical surfaces like a touchpad. A motion dataset was created using infrared cameras, touchpads, and IMUs. We then identified several useful physical constraints, such as joint co-planarity, rigid constraints, and velocity consistency. These principles help refine the finger-tracking predictions from an RNN model. By incorporating touch state detection as a cursor movement switch, we achieved precise cursor control. In a Fitts’ Law
study, MouseRing demonstrated input efficiency comparable to touchpads. In real-world applications, MouseRing ensured robust, efficient input and good usability across various surfaces and body postures.
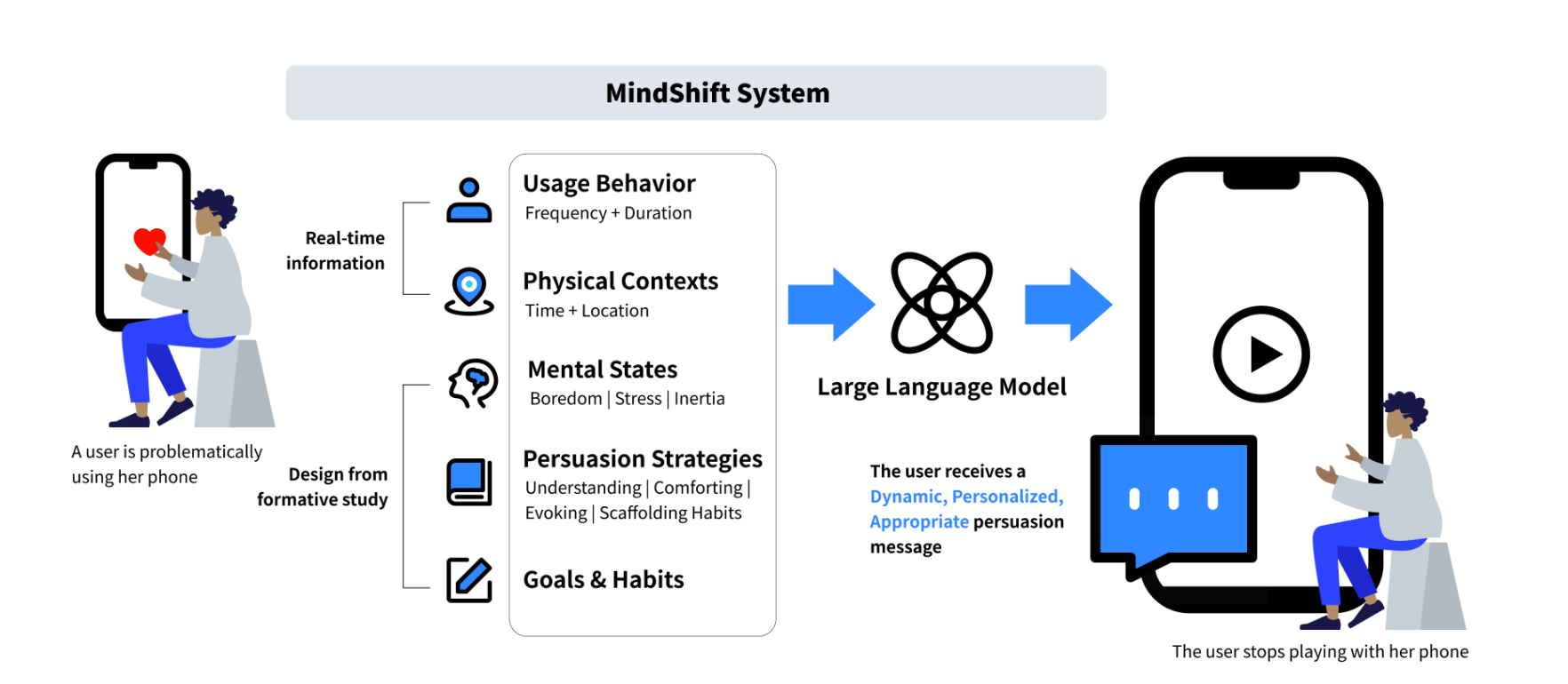
MindShift: Leveraging Large Language Models for Mental-States-Based Problematic Smartphone Use Intervention
Abstract
Problematic smartphone use negatively affects physical and mental health. Despite the wide range of prior research, existing persuasive techniques are not flexible enough to provide dynamic persuasion content based on users’ physical contexts and mental states. We first conducted a Wizard-of-Oz study (N=12) and an interview study (N=10) to summarize the mental states behind problematic smartphone use: boredom, stress, and inertia. This informs our design of four persuasion strategies: understanding, comforting, evoking, and scaffolding habits. We leveraged large language models (LLMs)
to enable the automatic and dynamic generation of effective persuasion content. We developed MindShift, a novel LLM-powered problematic smartphone use intervention technique. MindShift takes users’ in-the-moment app usage behaviors, physical contexts, mental states, goals & habits as input, and generates personalized and dynamic persuasive content with appropriate persuasion strategies. We conducted a 5-week field experiment (N=25) to compare MindShift with its simplified version (remove mental states) and baseline techniques (fixed reminder). The results show that MindShift improves intervention acceptance rates by 4.7-22.5% and reduces smartphone usage duration by 7.4-9.8%. Moreover, users

ContextCam: Bridging Context Awareness with Creative Human-AI Image Co-Creation
Abstract
The rapid advancement of AI-generated content (AIGC) promises to transform various aspects of human life significantly. This work particularly focuses on the potential of AIGC to revolutionize image creation, such as photography and self-expression. We introduce ContextCam, a novel human-AI image co-creation system that integrates context awareness with mainstream AIGC technologies like Stable Diffusion. ContextCam provides user’s image creation
process with inspiration by extracting relevant contextual data, and leverages Large Language Model-based (LLM) multi-agents to co-create images with the user. A study with 16 participants and 136 scenarios revealed that ContextCam was well-received, showcasing personalized and diverse outputs as well as interesting user behavior patterns. Participants provided positive feedback on their engagement and enjoyment when using ContextCam, and acknowledged its ability to inspire creativity.
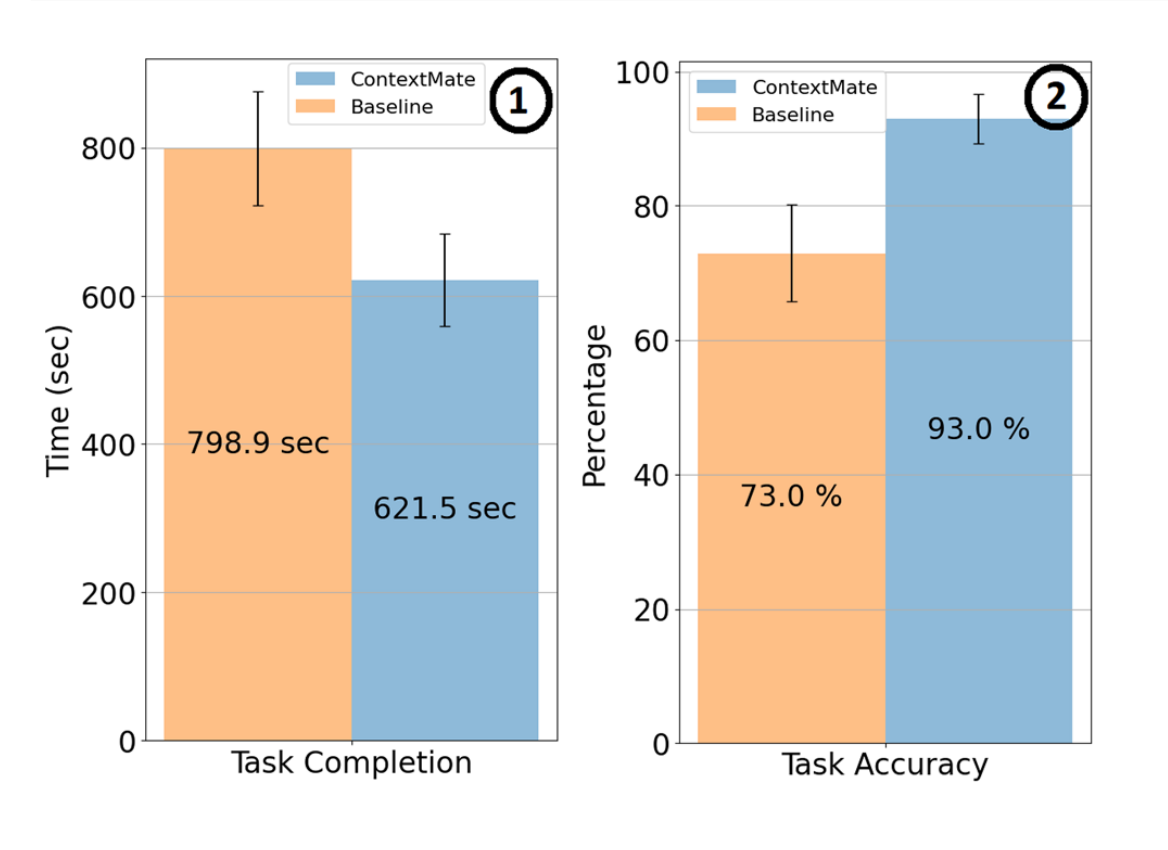
ContextMate: a context‑aware smart agent for efficient data analysis
Abstract
Pre-trained large language models (LLMs) have demonstrated extraordinary adaptability across varied tasks, notably in data analysis when supplemented with relevant contextual cues. However, supplying this context without compromising data privacy can prove complicated and time-consuming, occasionally impeding the model’s output quality. To address this, we devised a novel system adept at discerning context from the multifaceted desktop environments commonplace amongst office workers. Our approach prioritizes real-time interaction with applications, according precedence to those recently engaged
with and have sustained prolonged user interaction. Observing this landscape, the system identifies the dominant data analysis tools based on user engagement and intelligently aligns concise user queries with the data’s inherent structure to determine the most appropriate tool. This meticulously sourced context, when combined with optimally chosen prefabricated prompts, empowers LLMs to generate code that mirrors user intentions. An evaluation with 18 participants, each using three popular data analysis tools in real-world office and R &D scenarios, benchmarked our approach against a conventional baseline. The results showcased an impressive 93.0% success rate of our system across seven distinct data-focused tasks. In conclusion,
our method significantly improves user accessibility, satisfaction, and comprehension in data analytics.