论文成果 / Publications
2020
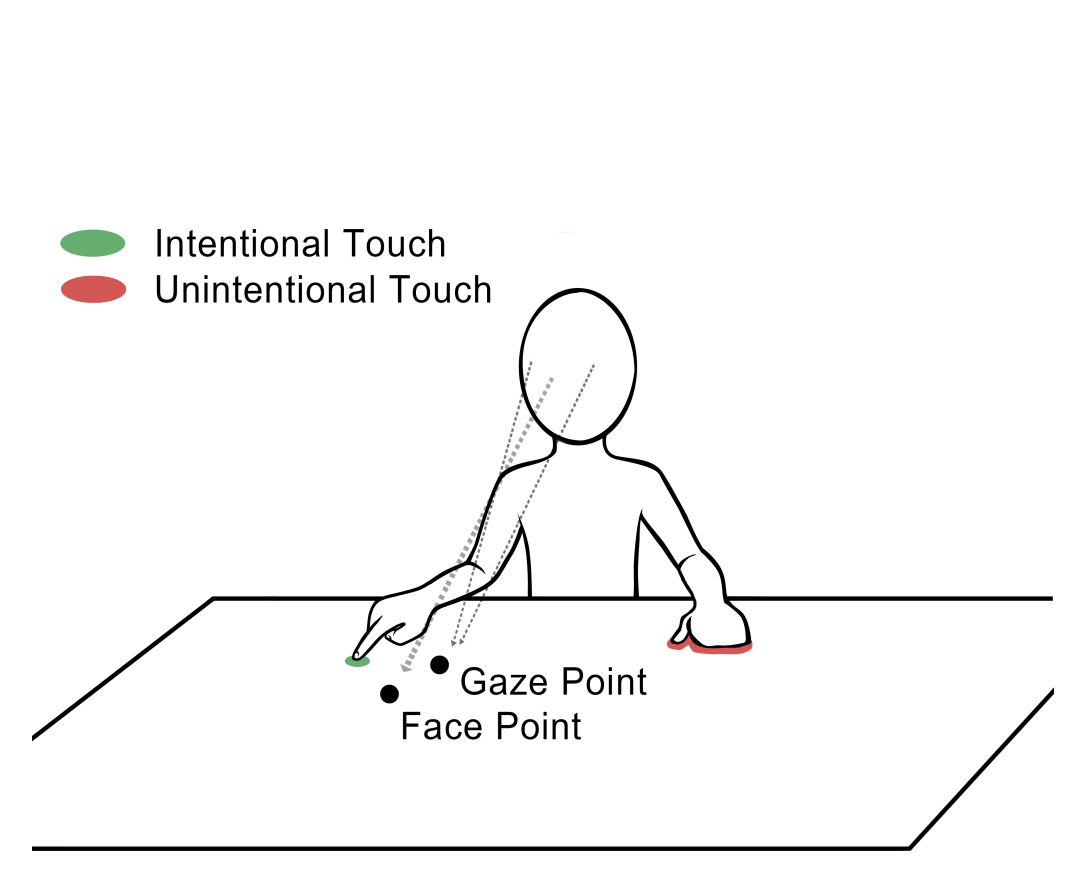
Recognizing Unintentional Touch on Interactive Tabletop
Abstract
A multi-touch interactive tabletop is designed to embody the benefits of a digital computer within the familiar surface of a physical tabletop. We leverage gaze direction, head orientation and screen contact data to identify and filter out unintentional touches, so that users can take full advantage of the physical properties of an interactive tabletop. We first conducted a user study to identify behavioral pattern differences (gaze, head and touch) between completing usual tasks on digital versus physical tabletops. Then we compiled our findings into five types of spatiotemporal features, and train a machine learning model to recognize unintentional touches. Finally we evaluated our algorithm in a real-time filtering system. A user study shows that our algorithm is stable and the improved tabletop effectively screens out unintentional touches, and provide more relaxing and natural user experience. By linking their gaze and head behavior to their touch behavior, our work sheds light on the possibility of future tabletop technology to improve the understanding of users’input intention.
Keep the Phone in Your Pocket: Enabling Smartphone Operation with an IMU Ring for Visually Impaired People
Abstract
We present a ring-based input interaction that enables in-pocket smartphone operation. By wearing a ring with an Inertial Measurement Unit on the index finger, users can perform gestures on any surface (e.g., tables, thighs) using subtle, one-handed gestures and receive auditory feedback via earphones. We conducted participatory studies to obtain a set of versatile commands and corresponding gestures. We subsequently trained an SVM model to recognize these gestures and achieved a mean accuracy of 95.5% on 15 classifications. Evaluation results showed that our ring interaction is more efficient than some baseline phone interactions and is easy, private, and fun to use.
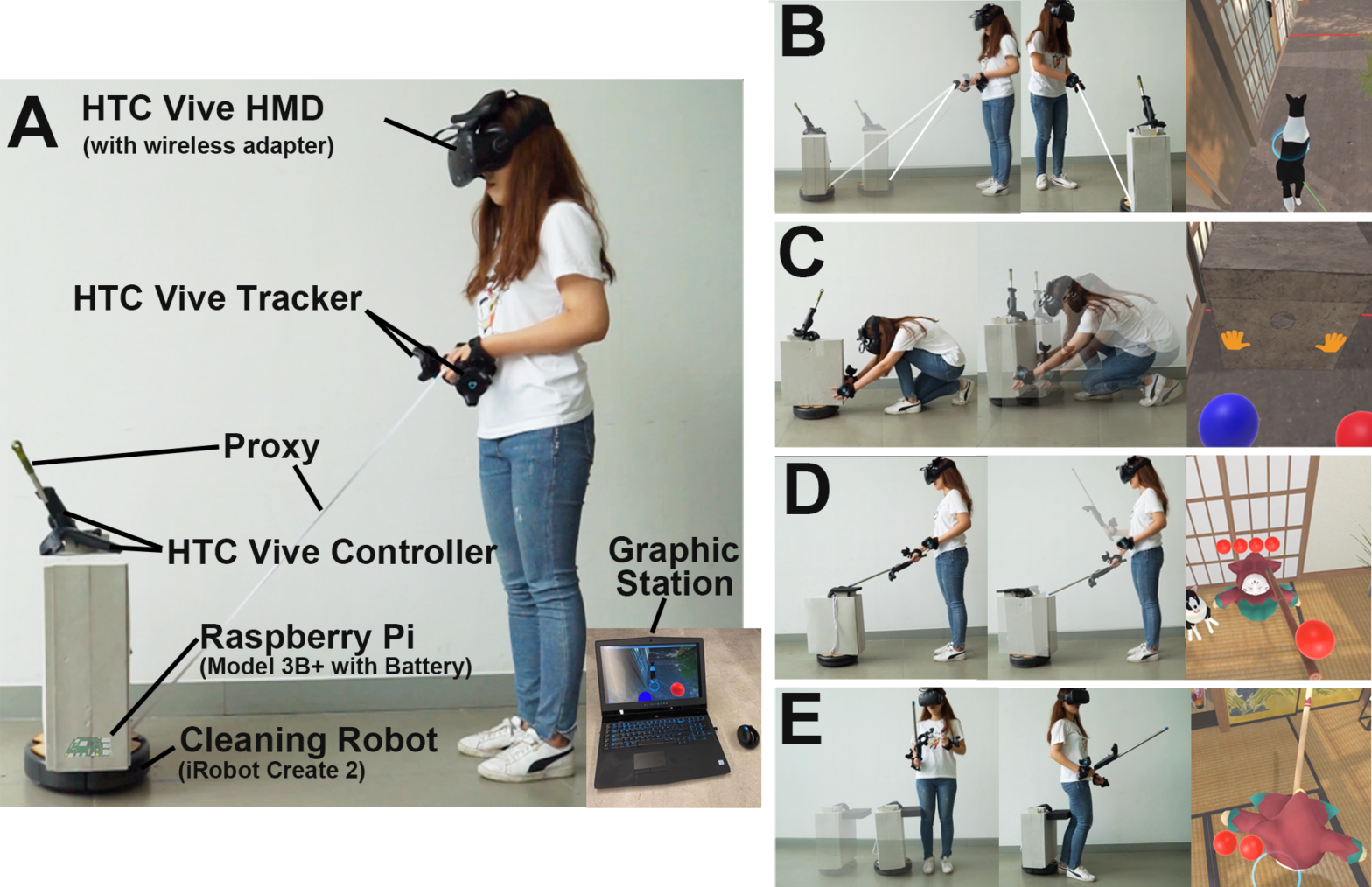
MoveVR: Enabling Multiform Force Feedback in Virtual Reality using Household Cleaning Robot
Abstract
Haptic feedback can significantly enhance the realism and immersiveness of virtual reality (VR) systems. In this paper, we propose MoveVR, a technique that enables realistic, multiform force feedback in VR leveraging commonplace cleaning robots. MoveVR can generate tension, resistance, impact and material rigidity force feedback with multiple levels of force intensity and directions. This is achieved by changing the robot's moving speed, rotation, position as well as the carried proxies. We demonstrate the feasibility and effectiveness of MoveVR through interactive VR gaming. In our quantitative and qualitative evaluation studies, participants found that MoveVR provides more realistic and enjoyable user experience when compared to commercially available haptic solutions such as vibrotactile haptic systems.
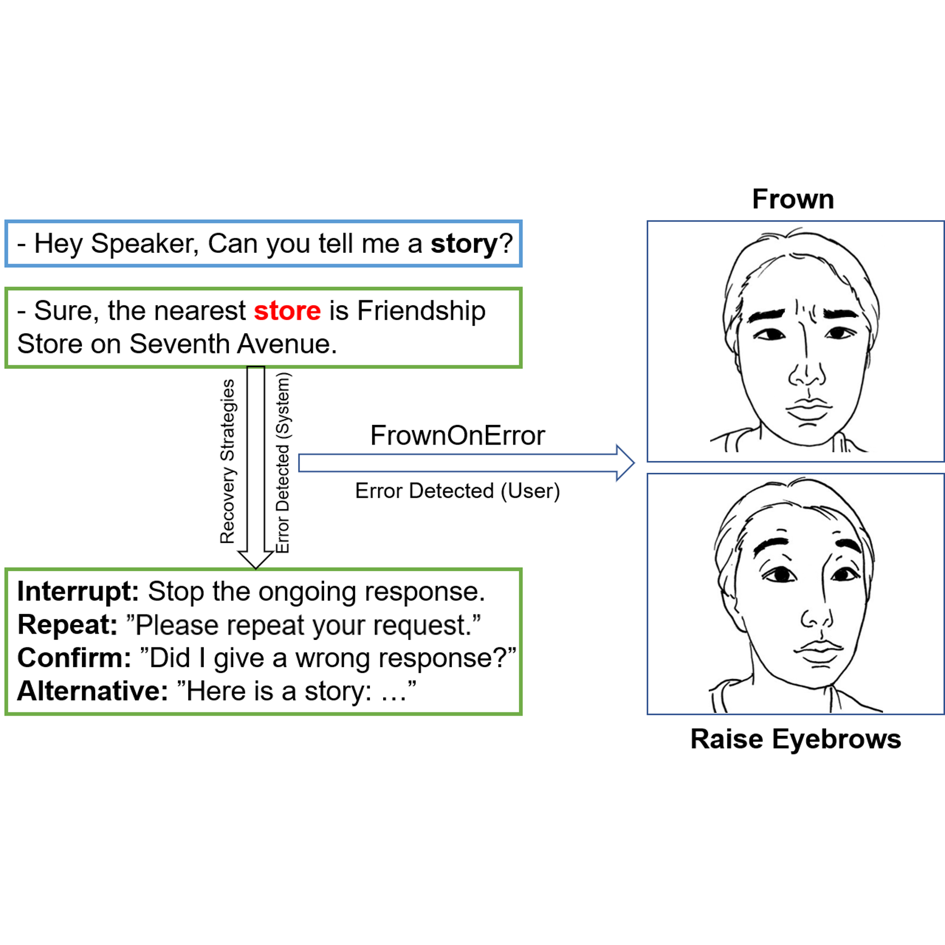
FrownOnError: Interrupting Responses from Smart Speakers by Facial Expressions
Abstract
In the conversations with smart speakers, misunderstandings of users' requests lead to erroneous responses. We propose FrownOnError, a novel interaction technique that enables users to interrupt the responses by intentional but natural facial expressions. This method leverages the human nature that the facial expression changes when we receive unexpected responses. We conducted a first user study (N=12) which revealed the significant difference in the frequency of occurrence and intensity of users' facial expressions between two conditions. Our second user study (N=16) evaluated the user experience and interruption efficiency of FrownOnError and the third user study (N=12) explored suitable conversation recovery strategies after the interruptions.
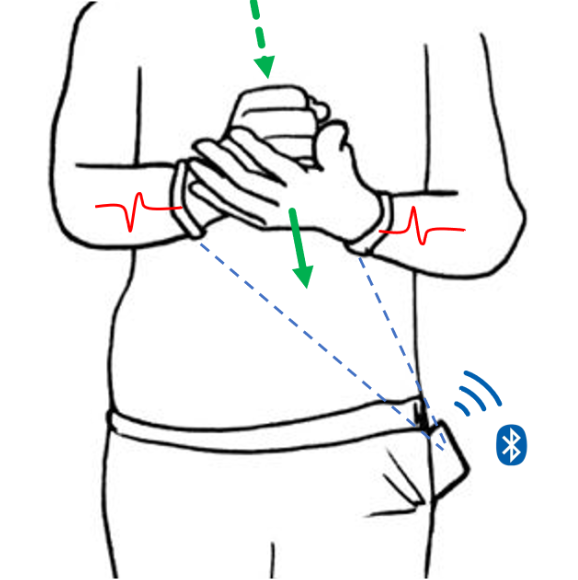
Designing and Evaluating Hand-to-Hand Gestures with Dual Commodity Wrist-Worn Devices
Abstract
We explore hand-to-hand gestures, a group of gestures that are performed by touching one hand with the other hand. Hand-to- hand gestures are easy to perform and provide haptic feedback on both hands. Moreover, hand-to-hand gestures generate simultaneous vibration on two hands that can be sensed by dual off-the-shelf wrist-worn devices. Our results show that the recognition accuracy for fourteen gestures is 94.6% when the user is stationary, and the accuracy for five gestures is 98.4% or 96.3% when the user is walking or running, respectively. This is significantly more accurate than a single device worn on either wrist.

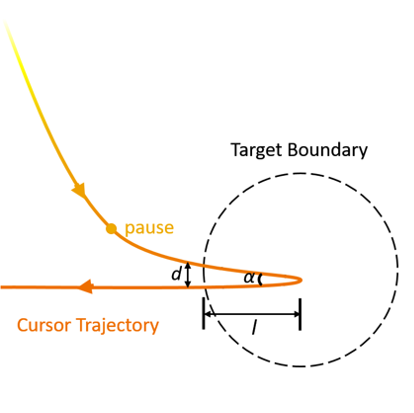
Investigating Bubble Mechanism for Ray-Casting to Improve 3D Target Acquisition in Virtual Reality
Abstract
We investigate a bubble mechanism for ray-casting in virtual reality. Bubble mechanism identifies the target nearest to the ray, with which users do not have to accurately shoot through the target. We first design the criterion of selection and the visual feedback of the bubble. We then conduct two experiments to evaluate ray-casting techniques with bubble mechanism in both simple and complicated 3D target acquisition tasks. Results show the bubble mechanism significantly improves ray-casting on both performance and preference, and our Bubble Ray technique with angular distance definition is competitive compared with other target acquisition techniques.
HeadCross: Exploring Head-Based Crossing Selection on Head-Mounted Displays
Abstract
We propose HeadCross, a head-based interaction method to select targets on VR and AR head-mounted displays (HMD). Using HeadCross, users control the pointer with head movements and to select a target and can select targets without using their hands. We first conduct a user study to identify users’ behavior differences between performing HeadCross and other head movements. Based on the results, we discuss design implications, extract useful features, and develop the recognition algorithm. In Study 2, we compared HeadCross to baseline method in two typical target selection tasks on both VR and AR interfaces. In Study 3, we compared HeadCross to three alternative designs of head-only selection methods.
CCCF2020|信息无障碍中的智能交互技术
Abstract
信息无障碍 (information accessibility) 是一个学科交叉的技术和应用领域,旨在用信息技术弥补残障人士生理和认知能力的不足,让他们可以顺畅地与他人、物理世界和信息设备进行交互。据中国残联统计,中国现有8500万残疾人,是世界上残疾人口最多的国家。其中,听力残疾 2000 万人,视力残疾 1200 万人,各类肢体残疾 2500 万人,智力残疾和精神残疾 1200 万人……随着社会老龄化程度加重,残疾人口数量也在持续增长。互联网和用户终端的普及,使得信息无障碍成为一个越来越值得关注的领域,目标是解决残障人士的信息访问甚至是生活服务问题。信息无障碍始于个人计算设备,IBM 在1984年首次开发了基于桌面操作系统的读屏程序,让盲人可以使用电脑。1997 年,万维网联盟 (W3C) 成立了网络无障碍推动 (WAI) 小组,推动网络页面的信息无障碍。随着人工智能技术的发展,语音识别、图像识别、手语翻译等技术也被应用到信息无障碍领域中,支持更多的残疾用户(比如聋哑人)通信和访问信息设备。微软在2018年推出了“人工智能无障碍计划”(AI for Accessibility),国内的互联网公司阿里巴巴、百度等也积极推出智能读图等无障碍交互应用。 在学术界,专门交流无障碍技术的国际会议是 ASSETS (ACM SIGACCESS Conference on Comput- ers and Accessibility),1994年是第一届。如今智能 手机上基于触摸的读屏系统原型就是在 ASSETS 2008 上提出的。2017 年,人机交互领域的旗舰会议ACM CHI (ACM CHI Conference on Human Factors in Computing Systems) 将无障碍列为十大方向之一。 我国于 2004 年举办了第一届中国信息无障碍论坛。2006 年,工信部把信息无障碍工作纳入“阳光绿色工程”,并由中国通信标准化协会 (CCSA) 开始系统化制定信息无障碍标准。2008 年,工信部发布了首个网站设计无障碍技术标准,信息无障碍在 “十三五”规划期间被纳入国家发展计划。 从研究和应用水平上看,信息无障碍总体还处于比较初步的状态。在应用上,针对信息访问和设备使用,具有基本功能的技术可以被应用, 但效果和效率等可用性指标都不高;在现实生活中,针对听障人士与他人交流、盲人独立出行等, 能支撑的新技术还处于原型和概念阶段。我们组织本期专题的目的,就是让读者了解无障碍领域目前存在的问题和研究进展,了解此交叉学科具有的重要研究与应用价值,希望更多的科技工作者能够介入或投身到相关研究中去,从各自的角度参与和贡献力量。
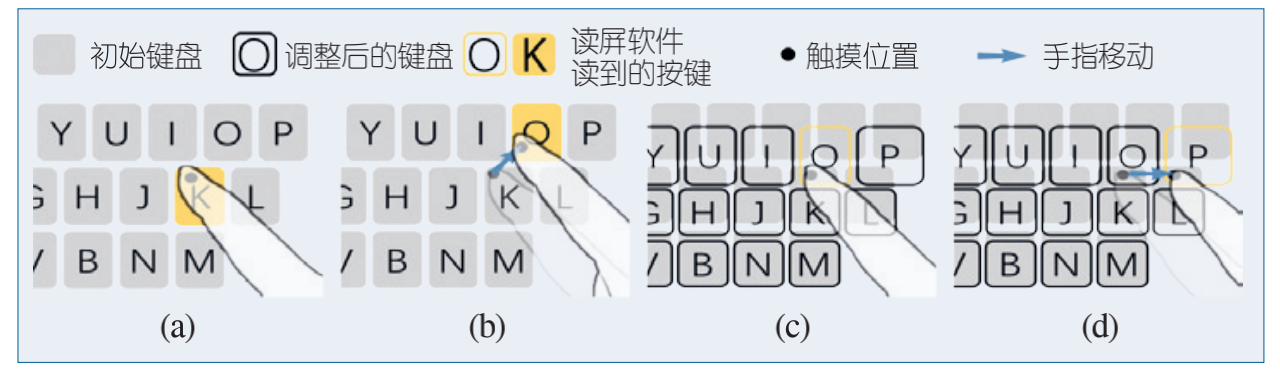
CCCF2020|基于字符级纠错的盲人智能键盘
Abstract
在当今的移动计算时代,智能手机对于盲人或视障用户而言,和对于明眼人用户一样,是不可或缺的存在。然而,对于视障用户来说,许多交互上的障碍影响了他们在移动计算方面的体验,其中一项便是文本输入。在智能手机上进行文本输入是一项有挑战的任务,甚至对明眼人用户来说也是如此,原因在于人们使用手指去精确地选择一个比较小的目标键是非常困难的。幸运的是,对于明眼人用户来说,几乎所有的现代触屏键盘都是所谓的“智能”键盘,因为它们有词级别的自动纠错能力。当用户输入一个词语分隔符(例如空格)之后,键盘会根据语言的上下文和空间的点击位置将用户的输入纠正为词典中的一个词。 但不幸的是,视障用户却无法享受这些便利,他们进行文本输入是一件十分困难的事情。其主要原因在于,现有的词级别的自动纠错键盘并不符合视障用户的输入行为。明眼人用户可以忽略输入过程中的错误字符,等待自动纠错算法来纠正这些错误。而视障用户无法这样做,他们使用读屏软件(例如安卓系统上的TalkBack和iOS系统上的VoiceOver)将字符逐个输入,直到当前字符被确认输入了才会继续输入下一个字符。为了输入某个特定的字母,视障用户首先在键盘上使用手指摸索着找到目标键所在的位置,然后抬起手指(或双击屏幕)确认输入。他们需要确保每个字母都被正确输入,因为 (1) 这样可以避免之后再修改这些错误所带来的较高成本;(2) 语音反馈中的错误相对于视觉反馈更加明显,视障用户更难以忽略输入过程中的错误。综上,读屏键盘并没有词级别的自动纠错能力,视障用户只能忍受较低的文本输入速度(低于每分钟5个词)。针对上述问题,我们提出了VIPBoard,一个在 不改变用户输入行为的基础上把自动纠错能力带给 视障用户的“智能”读屏键盘。VIPBoard 的主要功能由两个机制实现 :(1) 它可以根据语言模型和手指 的位置预测用户最可能输入的字符,并自动调整键盘布局,以使该字符所对应的按键处于手指接触的位置。这样,用户无须移动手指就能纠正输入,节省了时间和精力。(2) 键盘布局会进行缩放调整来确保所有的按键都能通过移动手指来访问,以保证在预测和布局调整不正确的情况下仍可以正常使用键盘。这两个机制提供了和传统非智能键盘一致的用户体验,并将学习成本最小化。VIPBoard 的优势建立在大多情况下对字符预测正确的基础上。