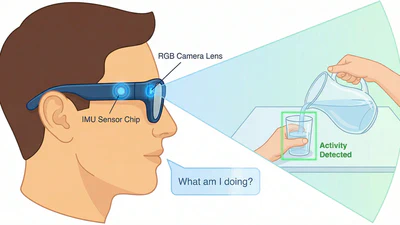
MMTSA: Multi-Modal Temporal Segment Attention Network for Efficient Human Activity Recognition
Efficient multimodal HAR using camera and IMU. Achieves 11% F1-score improvement with lower latency on edge devices.
Efficient multimodal HAR using camera and IMU. Achieves 11% F1-score improvement with lower latency on edge devices.